In May 2026 we had the chance to visit Athens SEO, an international conference focused on Technical SEO and AI in Search, designed to help search professionals enhance their skills, connect with industry experts, and stay updated on the latest trends in search automation and artificial intelligence.
In this article we’ve put together what we think were the most valuable technical takeaways from the two-day event, focusing on the core challenges and opportunities that caught our attention.
TL;DR
- Because 85% of AI referral traffic originates from bots that do not execute JavaScript, legacy Client-Side Rendering (CSR) leaves your platform completely invisible. Serving data cleanly in the initial HTML via Server-Side Rendering is a non-negotiable prerequisite.
- In the new era of e-commerce, AI search engines rely on Query Fan-Out, breaking a single user prompt into dozens of highly granular, undocumented sub-queries about (mainly) specs and variations. High-level category pages can no longer capture this intent, Product Display Pages must now serve as the primary source of truth - make sure they are optimised and accessible.
- Managing AI bots is a delicate balance between immediate infrastructure costs and long-term search visibility. By analyzing your raw server logs, aka the ultimate source of truth, you can make data-driven architecture decisions (based on what your infrastructure can manage) and deploy granular, precise controls over exactly what the bots can access.
- Architectural E-E-A-T is a thing: Scaling trust is a data-modeling problem, not a content problem. Move away from flat text strings and explicitly model authority by turning authors into verified database nodes. Never treat structured data as an afterthought. Leveraging robust Schema.org markup explicitly hands AI tools a deterministic entity graph they can instantly verify.
- If either the buzzwords ‘AI’ or ‘GEO’ are not included in your talk title, you’re apparently irrelevant
The Highlights
While it was tough to narrow down, here are the key (mostly technical) highlights we collected from the conference:
Taming the AI Crawlers: It’s a balancing act of give-and-take
Jamie Indigo (Director of Technical SEO, Cox Automotive) dove straight into AI crawler management, a deeply technical frontier that hits incredibly close to home for our team. As AI crawlers from ChatGPT, Perplexity, Claude, and Google multiply, our server logs, crawl budget, and content strategy are all affected.
It’s not just Google anymore. Each platform has its own rules (and they are ever-changing!).
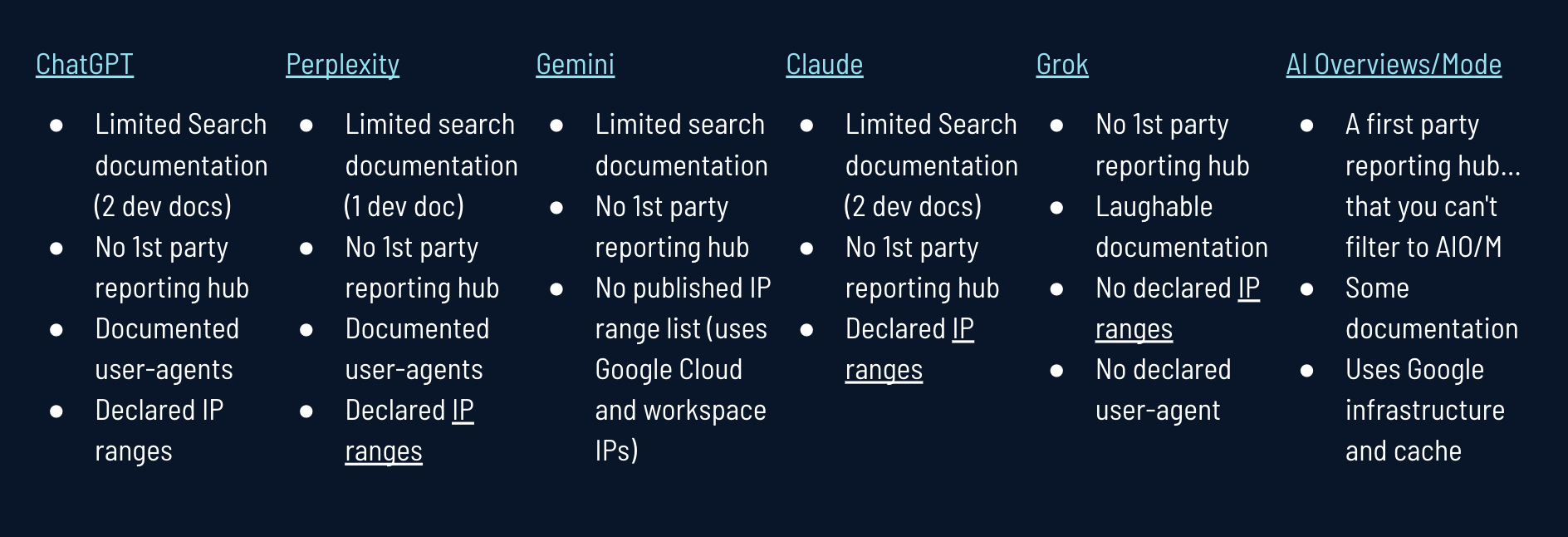
Because AI tools rarely provide transparent, first-party documentation, technical SEOs and engineers cannot rely on assumptions. Continuous empirical testing is the only way forward.
Jamie stressed the importance of having access to the raw server logs, as they are a source of truth. We should learn how to identify, segment, and manage AI bot traffic and turn what looks like a threat into a visibility opportunity. To audit our readiness for this new era of agentic web traffic, here are the critical questions we need to ask:
Define your Crawl-by-Purpose Ratio
This metric assesses what percentage of server resources is actively driving immediate business value versus what percentage is being absorbed by non-transactional scraping.
Most common bots can be segmented into 4 buckets: Training, User-Initiated, Search Indexers and Ads.
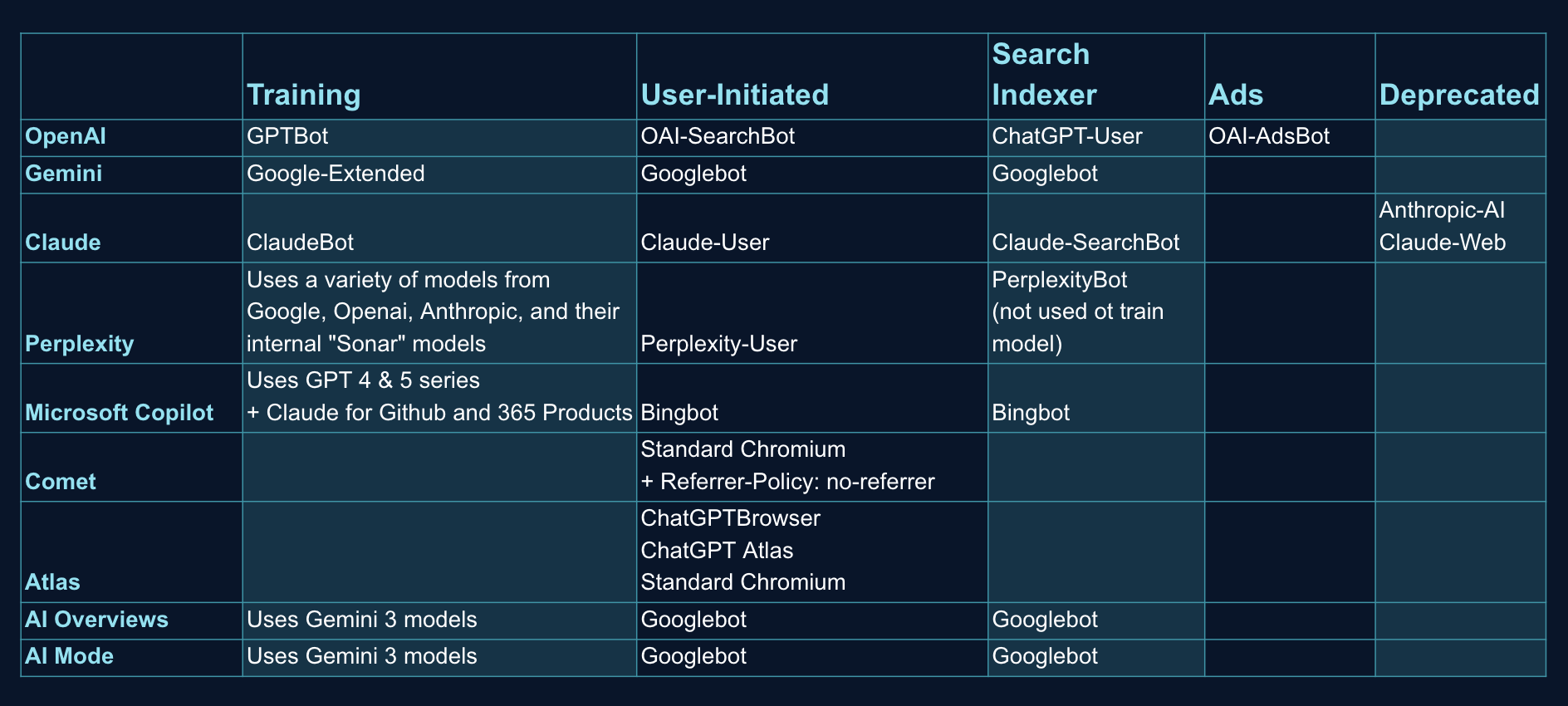
As Jamie bluntly put it, these bots are fundamentally lazy, dumb, and greedy. They don’t optimize their crawl paths out of the box, and blindly funding their resource consumption through your cloud infrastructure bill is bad engineering.
There is a training vs. inference tradeoff:
- Blocking training crawlers reduces baseline infrastructure load, but limits passive organic discovery within future model updates, as the model doesn’t “know” you.
- Blocking live inference crawlers eradicates real-time citation traffic and deeplinks from AI answers.
You do not have to resort to a nuclear option in robots.txt that completely blocks access. If you want to remain retrievable but prevent your core data assets from being fully digested, you can deploy precise controls
<data no-snippet>: Block specific page elements (div, span, section) from appearing in snippets/grounding. Preserves page ranking while hiding elected fragments.<meta name="robots" content="nosnippet">: Completely prevents an entire HTML page from being utilized for snippets or LLM training grounding without hiding the URL itself.X-Robots-Tag: nosnippet. For non-HTML resources, such as PDF files, video files, or image files.
The 85% JavaScript Blind Spot
Another super important note to keep in mind: 85% of AI referral traffic comes from platforms that do not execute JavaScript. (Source: AI Chatbot Market Share Worldwide | Statcounter Global Stats)
Make sure all important information on your site is easily accessible (in HTML, correct schema markup), while you block access to non-essential sections (e.g.block your API endpoints for non rendering bots). Without a robust Server-Side Rendering (SSR) or static fallback, you are practically invisible to these platforms.
Navigating E-Commerce Query Fan-Out at Scale
When modern AI engines process natural language requests, they don’t map to a singular generic keyword. Instead, they execute Query Fan-Out, creating dozens of sub-queries about specs, pricing, reviews, and alternatives. Most of these queries don’t exist in any keyword tool. The old e-commerce SEO approach built around category pages doesn’t work here. Now it’s the product pages that must have the answers.
Serge Bezborodov (CTO, JetOctopus) talked about that shift and shared practical steps that anyone who manages a massive website (think millions of SKUs) start using right away.

When a user asks an AI search engine for a product recommendation, the engine splits that intent path into dozens of highly granular data vectors covering precise specifications, real-time pricing, historical review patterns, and strict feature alternatives.
Query fanout matters because it breaks one keyword into multiple intent paths that most SEO strategies still aren’t structured to capture. Your Google Search Console is your ultimate source of truth. Just use your own GSC API: Mine your API (or use the Data Studio native connector) for long-tail keywords with Impressions.
Pro tip: Don’t forget to add multiple subfolders to GSC as Google does indeed return limited data for big websites. By querying the API across these segmented subfolders rather than the root domain, you force Google to expose distinct data pools, effectively bypassing the global truncation limit.
Product Pages: The Return of the King
For years, e-commerce SEO prioritized Category and Product Listing Pages (PLPs) as the primary pillars of organic traffic. But in an AI-first search ecosystem, the Product Detail Page (PDP) is reclaiming the crown. Because AI engines demand highly granular data to answer specific user prompts, they bypass high-level category pages entirely and head straight for the source. If your PDPs aren’t technically equipped to feed these bots what they need instantly, your marketplace is out of the game.
Building on the reality that the majority of AI bots do not execute JavaScript, if your platform relies entirely on Client-Side Rendering (CSR), an AI crawler hitting a product page will see nothing but a blank skeleton. No SSR? You’re invisible to AI bots.
As mentioned in the previous talk, taming the correct bots is an art. Sometimes innocent AI agents get blocked. Consumers are increasingly using specialized AI agents to conduct deep product research, compare configurations, and determine where to buy. Now the agent finds the shop, and the human makes the purchase. If your site blocks all non-standard bots out of habit, you aren’t just stopping scrapers, you are actively deflecting paying customers. Make sure your bot rules know the difference. (Sorry for blocking you, Serge!)
In the last slide, Serge sums up something we feel all along: to the boring Technical SEO, it still matters.
The all-you-can-E.E.A.T. buffet
While optimizing infrastructure for AI crawlers and preparing PDPs for query fan-out covers the technical delivery side of modern SEO, the actual payload, aka the content itself, must undergo a radical evolution.
Andrea Masoni & Alessia Mancini from GA Agency shared a great (travel sector) case where they used a practical framework for diagnosing and improving content quality at scale, GEO-optimised templates, and progress tracking. As mentioned, a page that ranks isn’t always a page that performs, and content maturity bridges that gap.
To stay visible in both traditional search and modern AI engines, the Alpitour (Italy’s leading tourism group) framework outlines a blueprint to structurally encode E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness):
- Provide exclusive insights. To stand out, your content needs Information Gain: unique insights or data points found nowhere else. For a large marketplace, this means programmatically sharing internal data, such as aggregated user metrics, real-time shopping trends, or price-to-performance ratios.
- Replace the generic brand voice with expert authors: The anonymous corporate voice doesn’t build trust anymore. Content should be credited to real internal experts and product managers. Shifting authorship to verified professionals signals to search engines that your content is backed by real-world experience.
- Build verified author pages: Don’t just add a text name to an article. Treat authors as distinct database entities. Create comprehensive Author Pages that gather their credentials, professional history, social profiles, and articles into a single profile that search bots can easily verify.
- Group content into dynamic hubs: Instead of publishing isolated blog posts, organize your content into centralized Guide Pages. These hubs automatically pull together relevant articles, practical guides, and targeted offers - all into a single thematic ecosystem. This structure makes it easier for search bots to crawl your site and recognize your topical depth.
- Link entities multi-directionally: In modern search, everything must connect. Set up clear, two-way internal links between your authors, products, and categories. This relational mapping builds a web of relevance, helping both Google and LLM networks recognize your platform’s authority.
- Add advanced structured data (Schema): E-E-A-T shouldn’t just be visible to humans; it must be explicitly coded for machines. Use deep integration of Schema.org markup (Person, Article, ItemList) to define technical relationships within the Knowledge Graph.
The Extras
SEO vs GEO vs AEO
It’s cool to see that us SEOs have still not collectively settled on our new rebranding.

Doesn’t matter though, because GEO is still low-key… SEO.
From Ranking Pages to Enabling Transactions
We have officially entered a hybrid era of e-commerce optimization. Success now requires a dual approach: hardening our traditional technical SEO foundations while simultaneously preparing for a market where AI models, shopping agents, and conversational interfaces dictate product discovery.
To help map out this transition, Aleyda Solís (International SEO Consultant & Founder of Orainti) provided a strategic roadmap in her talk, “Ecommerce AI Search Trends & Wins.” She summarized the exact areas where enterprise platforms need to expand their optimization efforts to capture value from these shifting consumer behaviors:

A Few Last Thoughts…
It is incredibly exciting to see how deeply AI adoption has matured. We’ve moved far beyond simple text rewriting and into the era of automated pipelines, advanced data analysis, and genuinely data-driven decision-making. By cutting out the tedious, repetitive work, AI is boosting overall productivity and allowing us to focus on what actually moves the needle.
One thing is certain: as the search landscape evolves, we are ready to navigate the unknown seas of GEO.

Eleni Tarantou,
On Behalf of Skroutz SEO Team.-
