![[Case Study] How we optimized our Crawl Budget](https://engineering.skroutz.gr/images/seo-crawl-budget-2019/seo-feature-image-skroutz.jpg)
Introduction
This is a story about the technical side of SEO on a large e-commerce website like Skroutz.gr, with nearly 1 million sessions daily and how we dealt with some significant technical issues we found a year and a half ago.
Let’s give you a sneak peek on the milestones of our efforts, which are covered in this case study. During the last 1.5 year, we managed to:
- Decrease our index size by 18 million URLs while improving our Impressions, Clicks and Average Position.
- Create a real-time crawl analyzer tool that can handle millions of URLs.
- Implement a custom alert mechanism for important SEO index and crawl issues.
- Automate the technical SEO process of merging or splitting e-commerce categories.
If you are interested to see why and how we did all the above, grab a seat!
Table of Contents
Part 1: SEO Analysis (February 2018)
› What issues initiated our analysis
› How we did the AnalysisPart 2: Action Plan and Execution (Feb 2018 - June 2019)
› Action Plan
› Execution
But before we take off, let us introduce ourselves.
Skroutz.gr is the leading price comparison search engine and marketplace of Greece and a top-1000 ranked website globally by Similar Web. Skroutz.gr helped its merchants generate a Gross Merchandise Volume (GMV) of €535 Million in 2018 (≈20% of Greece’s total Retail Ecommerce GMV).
Except for the main B2C price comparison service, Skroutz.gr also provides a B2B price comparison service and a new food online delivery service for the Greek market, namely SkroutzFood. Finally, Skroutz.gr operates its own marketplace of 500+ merchants.
SEO Challenges in Large Sites: The case of Skroutz.gr
So, what challenges does a Site with millions of pages encounter?
First of all, imagine the difficulties you have when you optimize your Rankings for an average-sized site, such as keyword research and monitoring, on-page SEO, etc. Now think about the same things on a million-page size website; You have to deal with a vast amount of data and automate things in a way that does not compromise quality.
Besides this, SEO is not just rankings…
Indeed, large website SEOs have another big headache: Crawling and Indexing. These essential steps take place even before Google ranks your content and can be extremely complicated on huge sites.
Note: In this case study we focused on the Google Search Engine and GoogleBot. However, all search engines are operating similarly.
Most problems which occurred are related mostly to Crawl Budget and Duplicate Content. More specifically:
- Crawl Budget: Google has a crawl rate limit for every website. If the website has fewer than a few thousand URLs, it will be usually crawled just fine. However, if you have a site with a million or more pages, you need to enhance your structure so that crawlers have a far easier time accessing and crawling your most important pages
- Duplicate Content: If the same content appears at more than one web address, you’ve got duplicate content. While there is no duplicate content penalty, duplicate content can drive, sometimes, on ranking and traffic drops. As Moz says, this happens because GoogleBot *don’t know whether to direct the link metrics (trust, authority, anchor text, link equity, etc.) to one page, or keep it separated between multiple versions and, secondly, it doesn’t know which version(s) to rank for query results.

For example, Skroutz.gr has more than 3,000,000 products in 3,000 categories. It also uses a faceted navigation with more than 13,000 filters (which can be combined - up to 3 filters), three sorting options and an internal search function. Most of these options produce a unique page (URL).
Thus, large sites’ administrators have to:
- automate the monitoring the site’s SEO performance
- watch out for thin or duplicate content issues so that they don’t confuse Google about what pages are essential for them
- control over what pages are crawled and indexed
Part 1: SEO Analysis (February 2018)
What issues initiated our analysis
If everything goes like clockwork, most of your rankings are on top 3 positions and the organic traffic growth is stable, then, it is hard to suspect that something might not be going so well SEO-wise. That was the case with Skroutz.gr back in 2018.
If you look at the graph of GA sessions over the past five years below, it’s evident that our traffic is increasing every year with a 15-20% YoY organic growth, even surpassing 30Μ monthly sessions (80% of that traffic is organic).
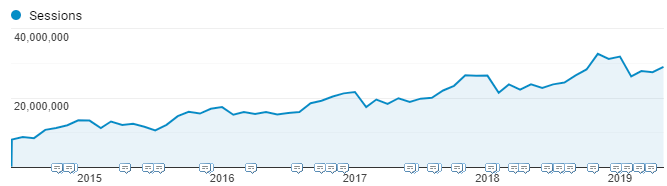
So what was the first sign that something was not going as expected? Three issues raised flags, especially when we realized the correlation between them.
1. Index Size
The first one was the index size we saw on Search Console (nearly 25 million URLs) compared to the “real” number of our pages that we thought we had.
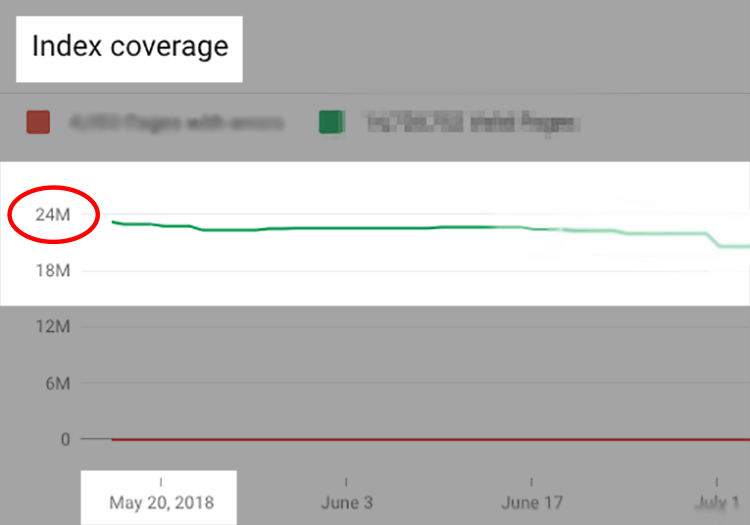
2. Increased time for new pages to get indexed and rank high
Delays in rankings recovery were more evident in cases we had to break a broad category into 2-3 subcategories. This kind of splitting produces many new URLs, as well as many 301s redirects from the old URLs to the new ones (e.g., old filter URLs).
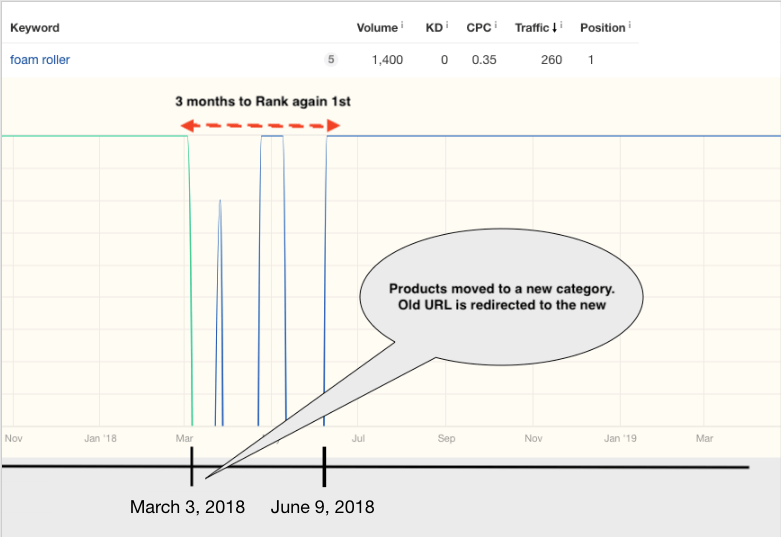 Ahrefs History Chart for “foam roller” keyword
Ahrefs History Chart for “foam roller” keyword
For example, look at the data above from Ahrefs History Charts for the keyphrase “foam roller” (click here to see Greek SERPs). Foam Roller products used to be in a broader category called Gym Balance Equipment (green line). On 03/03/2018, the content team decided to create a new category named Foam Rollers (blue line) and moved the relevant products there.
As you can see, historically, we ranked on 1st place for “foam rollers” with the internal search page skroutz.gr/c/1338/balance_gym.html?keyphrase=foam+roller. On 03/03/2018, we created skroutz.gr/c/2900/foam-rollers.html category and we redirected the first URL, plus a few hundred relevant URLs (e.g., skroutz.gr/c/1338/balance_gym.html?keyphrase=foam+rollers), to the latter.
Based on previous years’ stats, a new URL needed just a few days to a couple of weeks to recover it’s rankings, after the consolidation of the signals. Yet, in this case, it took almost three months (!) to rank in the first place. Besides this, old redirected URLs remained indexed for months instead of being removed after a few days. That indicated that our crawling efficiency had decreased over the years.
3. Increased time for metadata to refresh in Google Index
Titles and Meta Descriptions weren’t updated in Google’s index as fast as in the previous years, especially for pages with low traffic.
As a result, fresh content and schema markups (availability, reviews, and others) weren’t reflected in Google SERPs within a reasonable time.
How we did the Analysis
Step 1 - A first look at the problem
At first, we wanted to validate our concerns about the index bloat of 25M pages. So, we tried to figure out how many out of the 25M pages, were actually supposed to be in the SERPs.
We drilled down the different types of landing pages, calculating an estimation of:
- the number of currently indexed pages per type, using Google Search Operators
- their share of the total traffic, using Internal Analytics tools
- the number of indexed pages we should have, based on some criteria like current or potential traffic
| Type Of Page | Current Estimated Indexed Pages | Share of Total Organic Traffic | Indexed Pages we should have |
|---|---|---|---|
| Homepage | 1 | 24% | 1 |
| Product Pages [like Apple iPhone XR (64GB)] | 4.5M | 20% | 3M |
| Clean Category Pages [like Sneakers] | 2500 | 25% | 2450 |
| Category Filter Pages [like Stan Smith Sneakers or Nike Sneakers] | 2.5M | 10% | 1.5M |
| Internal Search Pages [like ps4] | 14M | 20% | 1M |
| Other Pages (Blog, Guides, Compare Lists, Pagination, Parameters) | 4M | 1% | 1M |
| Total | 25M | 100% | 6.5M |
The results were stunning.
- Actually indexed pages versus our estimated pages differed by a count of nearly 19 million URLs
- The Internal Search pages index bloat seemed the most crucial issue. Probably we had tons of meaningless, regarding traffic, indexed pages
- Product and Filter Pages had a reasonable amount of low-quality pages
- Pagination Pages were the top suspect of the 4M pages of “Other Pages” type. This announcement might explain why :-)
To tackle these issues, we all agreed that we should face the problem starting with a quick sprint and following-up with more sophisticated solutions down the road.
Step 2 - Setting up the team and the tools
After the above analysis, we formed a wider vertical “SEO purpose” team, which included SEO Analysts, Developers and System Engineers. This team would analyze the problem deeper, create an action plan and implement the proposals.
In our first meeting, we decided that an extensive crawl analysis is needed to fully understand the magnitude of the problem. We chose to set up an in-house real-time crawl monitoring tool, instead of a paid solution for the following reasons:
- Scalability: analyze more than 25 million pages and see the changes in behavior every time we needed.
- Real-Time Data: see the impact on the behavior of the crawler, right after a significant change
- Customization: customize the tool and add whatever function we wanted for every different situation
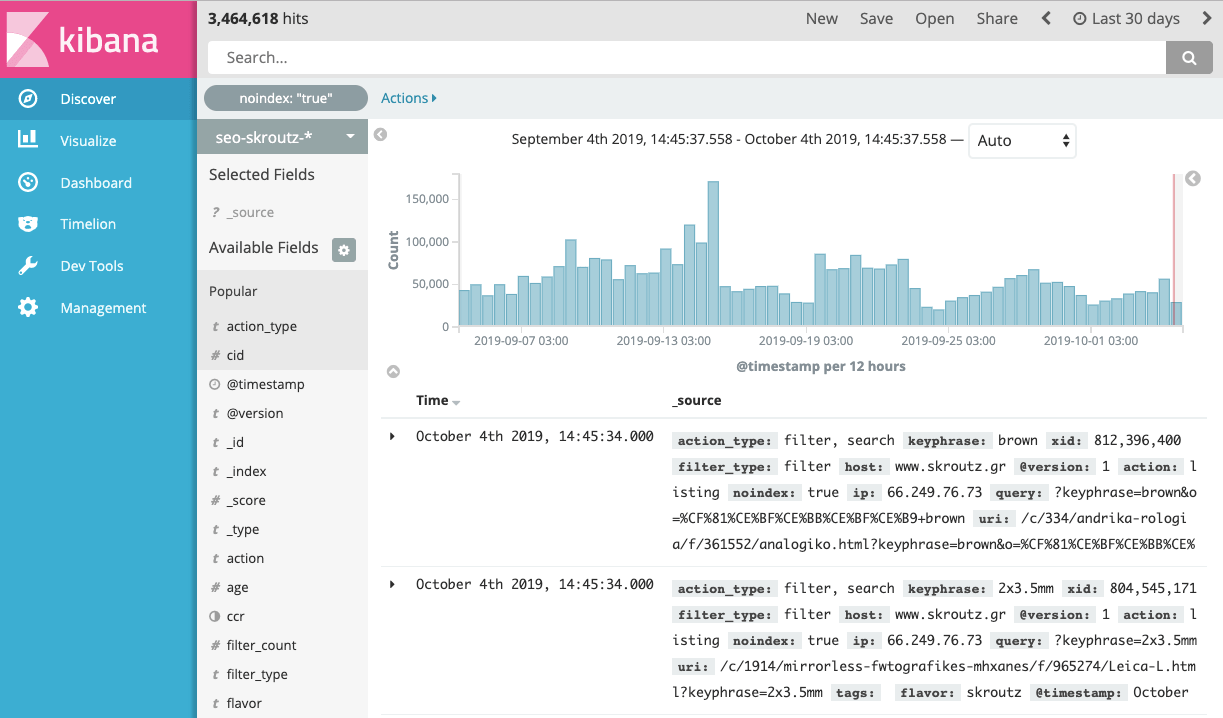
Note: Depending on your needs, you can use other paid tools such as Deepcrawl or Botify, which have some handy ready-to-use features.
As we already had some experience with the ELK Stack (this is one of our primary analytics tools), we decided to set up an internal crawl monitoring tool using Kibana.
Kibana is a powerful tool and helped us find a lot of significant crawl issues. If we had to choose just one thing that expanded our capabilities on crawl monitoring, that would be the annotation of pageviews with rich meta tags. With the use of rich meta tags, URLs carry additional structured information which provides a way to query a specific subset.
For example, let’s say that we have the URL: skroutz.gr/c/3363/sneakers/m/1464/Nike/f/935450_935460/Flats-43.html?order_by=popularity
Some of the information that we inject on that URL is the following:
- Page Type: Filter Page (other option could be Internal Search Page for example)
- Category ID: 3363
- Number of Filters Applied: 3
- Type of Filters: Normal Filter (Flats), Brand (Nike), Size (43)
- HTTP Status: 200
- URL Parameters: ?order_by=popularity
With that kind of information we are able to answer questions like:
- Does GoogleBot crawl pages with more than 2 filters enabled?
- How much does the Googlebot Crawl a specific popular category?
- Which are the top URL parameters that GoogleBot crawls?
- Does GoogleBot crawl pages with filters like “Size” which are nofollow by default?
Tip: You can use this information, not only for SEO purposes, but also for debugging.
For example, we use page load speed information to monitor the page speed per Page Type (Product Page, Category Page etc.) instead of monitoring just the average site speed.
Imagine how much you can drill down to find Googlebot’s crawl patterns using simple Kibana Queries.
How we inject the URL information
We use custom HTTP headers. These headers flow through our application stack and any component, like our Realtime SEO Analyser, can extract and process the information it needs. At the end, and before the response is returned to the client, we strip meta headers off the request.
To sum things up, Kibana gave us the ability to do three critical things:
-
See every single Google Bot crawl hit on a real-time basis
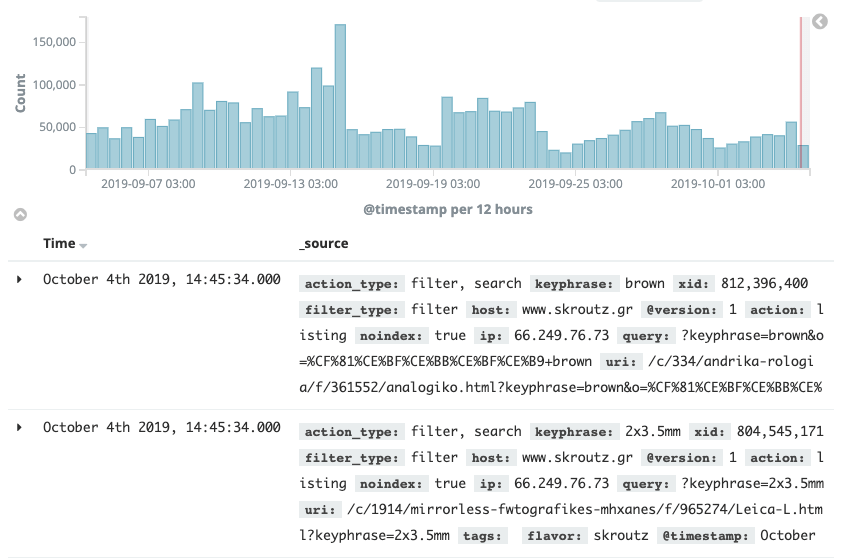
-
Narrow results with Filters such Product Category, URL Type (Product, Internal Search, etc.) and many more

-
Create Visualizations or Tables to monitor the crawl behavior thoroughly
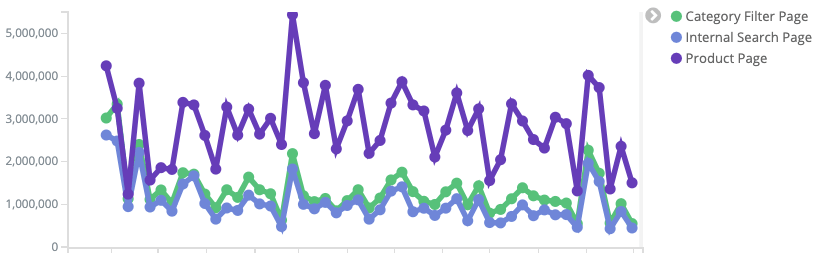 The line chart shows monthly crawls for Category Filters, Internal Search and Product Pages.
The line chart shows monthly crawls for Category Filters, Internal Search and Product Pages.
Step 3 - Conclusions of the Analysis
After much digging in through the crawl reports combined with traffic stats and at least one month of continuous monitoring on both real-time data and previous months’ log data (at least ten months), we had, at last, our first findings. We will sum up the most important below:
The Good
- GoogleBot crawled our most popular product pages (200k out of 4.5M) almost every day. These pages had high authority and many backlinks, so it was kind of expected
The Bad
- With an average daily crawl budget of 1M and our index of 25M, Googlebot could only crawl 4% of our total pages every day
- More than 50% of our daily crawl budget was spent on internal search pages. Besides this, most of those pages didn’t have traffic at all
-
In addition to the above, we saw a weird pattern, with a significant volume of internal search page URLs with the same generic keyphrase. For example, “v2” keyphrase was present on thousands of URLs. Examples:
We never thought that the combinations of internal searches with category pages would be crawled and indexed at such a high rate.
Part 2: Action Plan and Execution (Feb 2018 - June 2019)
Action Plan
After the analysis, our team decided on the next actions. Based on the findings, the most crucial problem was the crawl and index bloat of URLs with Internal Search Queries. We suspected the index bloat to be the main cause of the issues mentioned in Part 1.
We devised an action plan for the upcoming months consisting of two different projects:
A. Primary Crawl Budget Optimization (CBO) Project:
- Find and fix crawling loopholes which create more and more indexable internal search pages
- Decrease the index size of internal search pages by removing or consolidating those pages accordingly
B. Secondary Crawl Budget Optimization (CBO) Project:
- Enhance the crawl and indexing phase of new URLs when we create a new category or when we merge two or more categories into one. We saw that rankings were very slowly recovered in such cases
- Create an alert mechanism for important crawl issues
Execution
A. Primary Crawl Budget Optimization (CBO) Project:
1. Find crawling loopholes
At first, we wanted to see if any loopholes in our link structure allowed Googlebot to find new crappy internal search pages.
Before we start with the execution, it would be helpful to fully understand the way that our search engine works and how internal search pages are created.
Search Function on Skroutz.gr
As we said earlier, Skroutz.gr has always had search at the forefront, meaning that the vast majority of our users search for a product instead of just browsing. In fact, we have more than 600,000 searches per day!
That’s why we have a dedicated Search Team of 5 engineers who strive to enhance the experience of the user after he types a query inside the search box. The Search Team has created dozens of mechanisms to make our search engine return, in most cases, high quality and relevant results to the user. That’s why our bounce rate on those pages is very low (under 30%), near the site’s average.
Internal Search Pages: How are they created?
Firstly, we should point out that all internal search pages of Skroutz.gr have the parameter “?keyphrase=” on the URL.
There are 2 types of internal search pages; Let’s see which they are.
After a user inputs a query into the search box, our search mechanism will try to find the most relevant results from all the categories and return
- a mixed category search page. Example: skroutz.gr/search?keyphrase=shoes
- a dedicated category search page. Example: skroutz.gr/c/3363/sneakers.html?keyphrase=shoes
Important note: Every link of a mixed category search page, point to a dedicated category search page. On our example, if a user is on skroutz.gr/search?keyphrase=shoes and clicks on “Sneakers”, he will be moved to skroutz.gr/c/3363/sneakers.html?keyphrase=shoes.
That’s how an internal search page is created. 95% of indexed internal search pages are dedicated category pages.
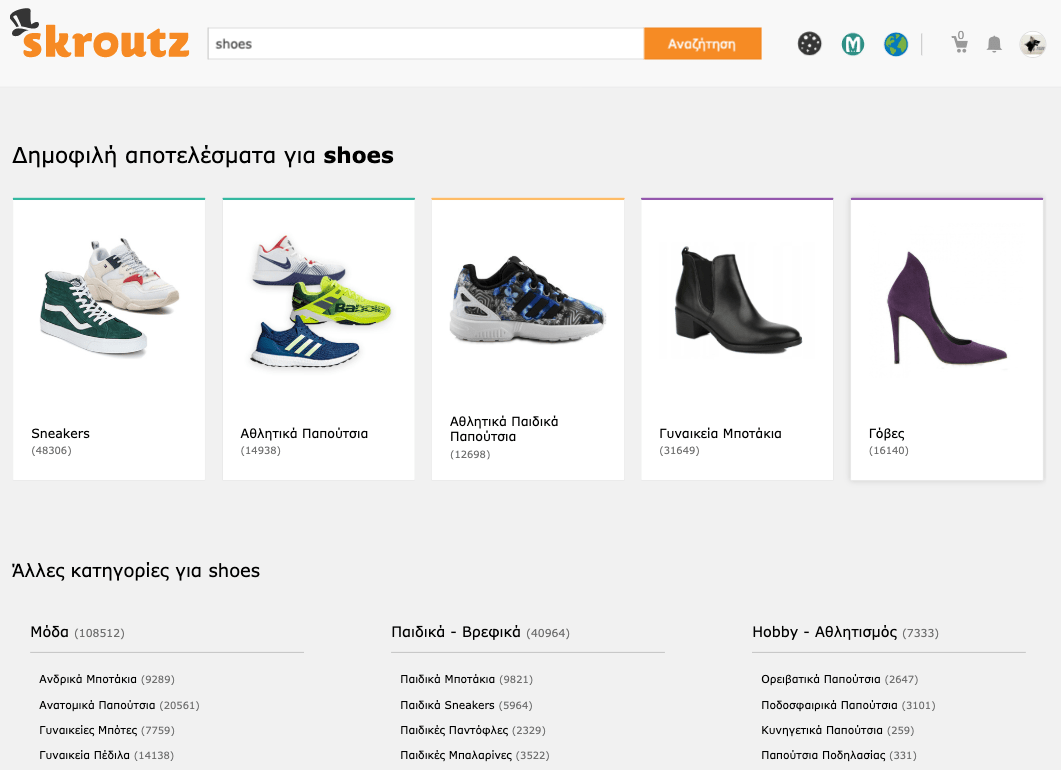
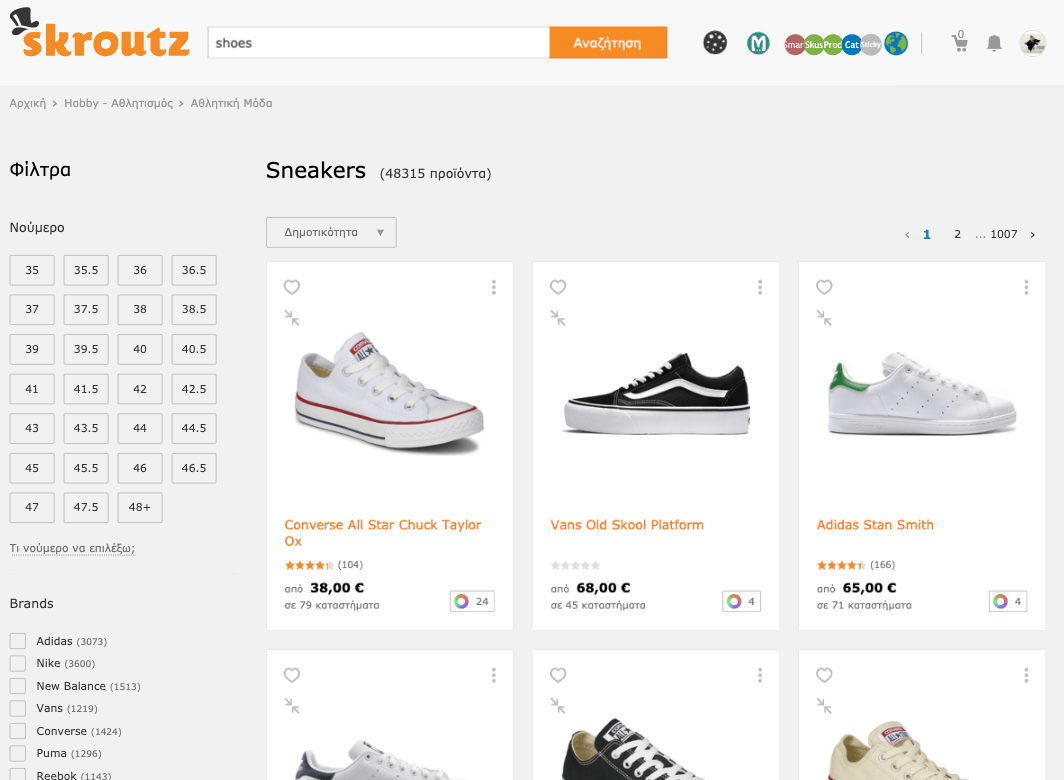
It is now apparent what the loophole was… The few mixed category search pages had dozens of follow links to dedicated category search pages with the same query. With this loophole, every different search query could create hundreds of category internal search pages.
That’s why skroutz.gr/search?keyphrase=v2 was creating tons of new dedicated category internal search pages like
- skroutz.gr/c/3363/sneakers.html?keyphrase=v2
- skroutz.gr/c/663/gamepads.html?keyphrase=v2
- skroutz.gr/c/1850/Gaming_Headsets.html?keyphrase=v2
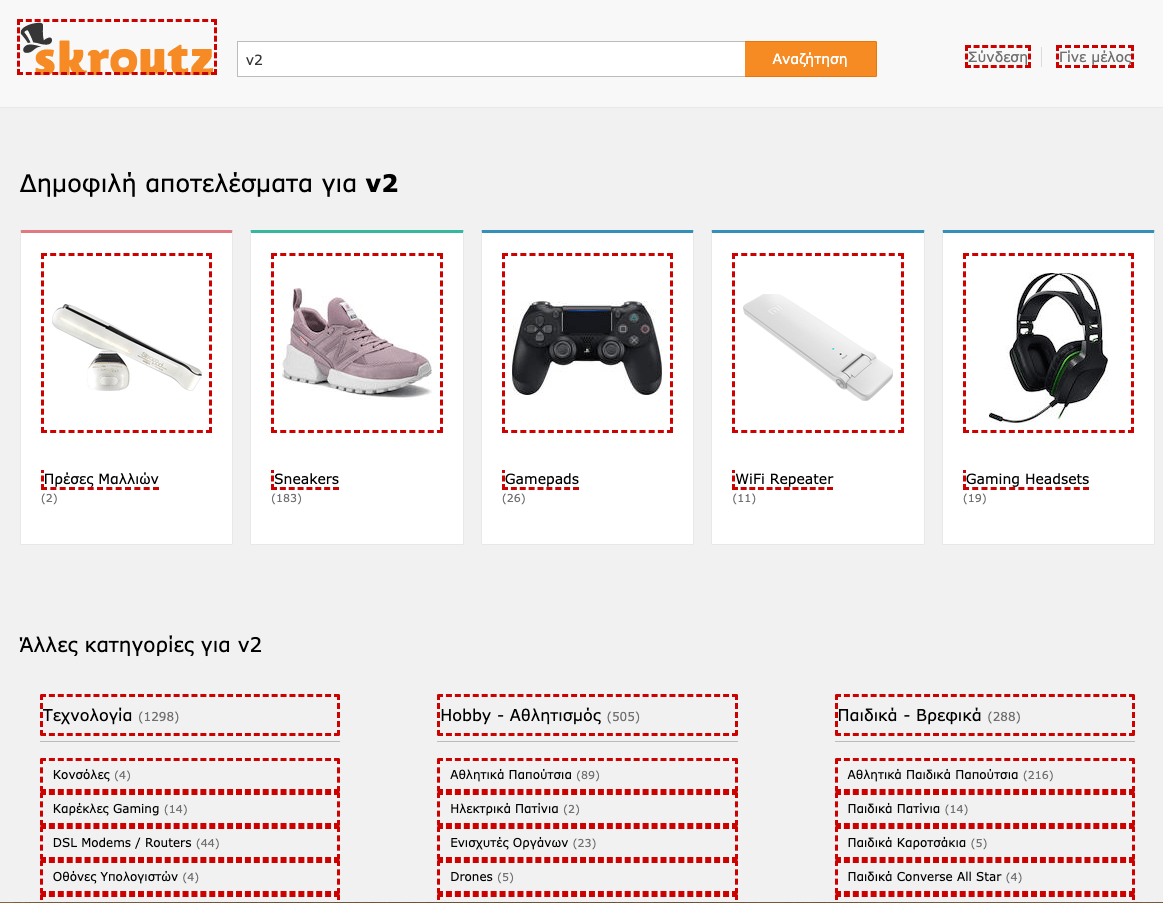 Googlebot can follow all red links. Thus every time it had access to a mixed category page, it could follow and crawl hundreds of new internal search pages for every different category that matched with user query.
Googlebot can follow all red links. Thus every time it had access to a mixed category page, it could follow and crawl hundreds of new internal search pages for every different category that matched with user query.
We fixed this issue by
- making all those links no-follow, except for some valuable, valid keyphrases (we will explain what a valid keyphrase is shortly)
- checking browsing and UX stats of the 70,000 most popular internal searches and redirect 20,000 of them directly inside a specific category filter or internal category search. As a result, both Googlebot and users won’t see the mixed category pages when there is no reason.
For example, we saw that >95% of the users who search for iphone wanted to see the mobile phone and not any accessories. So, instead of showing a mixed category page:
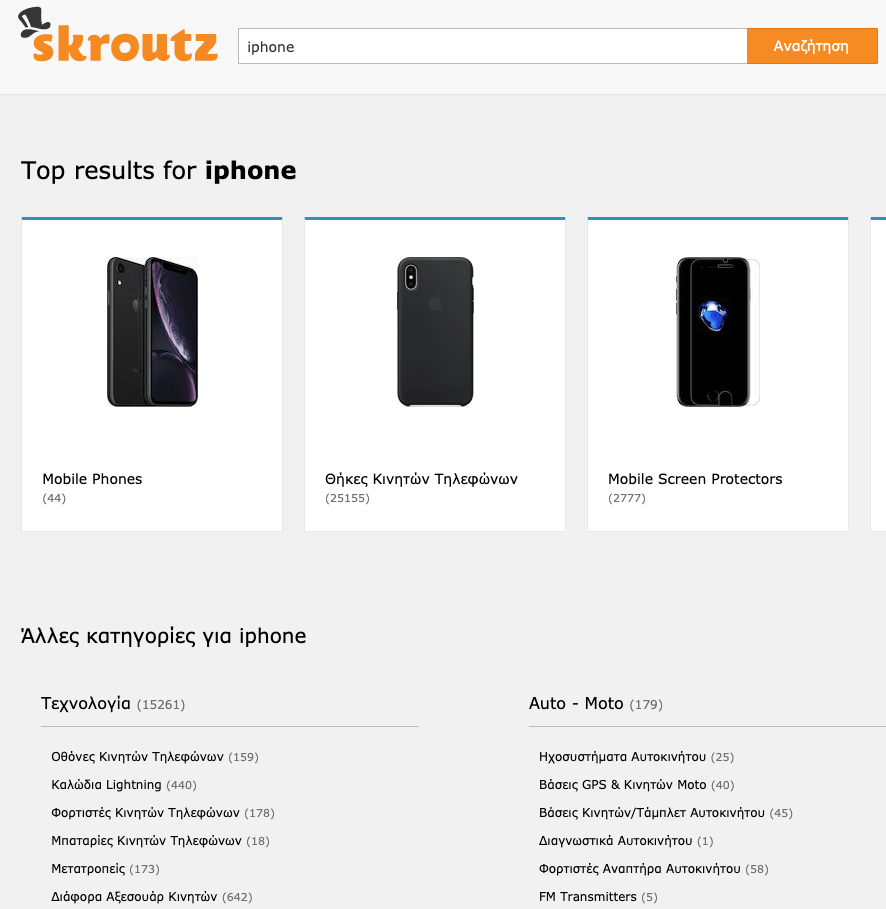
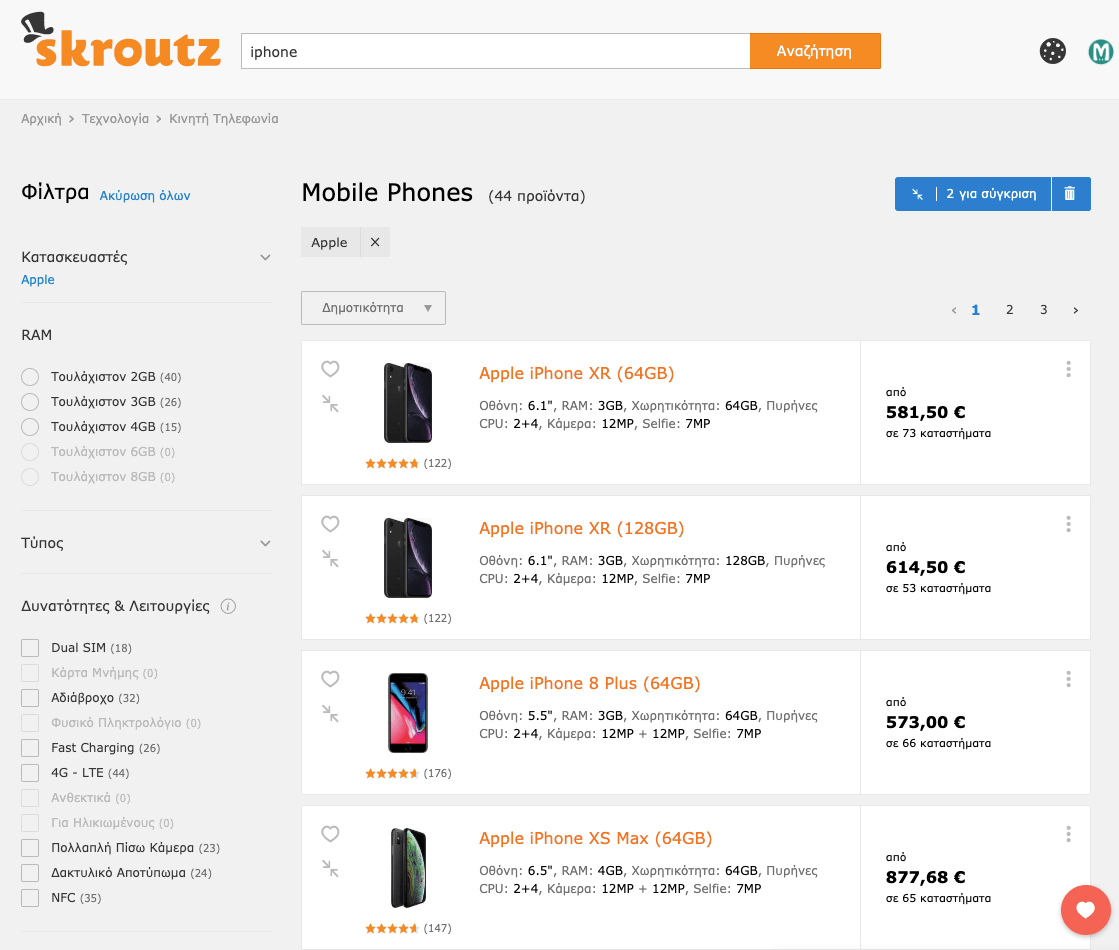
We redirect the user directly to a dedicated category search, based on their search intent:
2. Decrease index size
After the fix of the issue with the mixed category pages, like skroutz.gr/search?keyphrase=v2, which created more and more new dedicated category search pages, it was time to deal with the latter.
Dedicated category search pages, like skroutz.gr/c/3363/sneakers.html?keyphrase=v2, had an index of enormous size. So, we had to see how many pages are crawled by Googlebot and which of them had the quality to be indexed.
This task took us more than one year to finish (February 2018 till June 2019). It was massive and expensive in terms of hours and workforce, but it was worth it.
For this task, we decided to create a mechanism so that the SEO team could consolidate our no-index pages without the involvement of a developer.
But how and where could we consolidate the internal search pages?
That was pretty easy! We found out that most of the internal search URLs were near duplicates of existing category filters. Example:
- skroutz.gr/c/25/laptop.html?keyphrase=ultrabook (Internal Search Page)
- skroutz.gr/c/25/laptop/f/343297/Ultrabook.html (Filter Page)
So, what have we done?
At first, we created a dashboard with all internal search keyphrases for every category, combined with traffic and number of crawls (we called it Keyphrase Curation Dashboard). As we said earlier, every keyphrase may be present on more than one internal search URL.
Then, we added quick action buttons, so the SEO team could eventually do the following actions, without the help of a developer:
- redirect (Consolidate)
- noindex or
- mark the keyphrase as a valid, valuable internal search URL
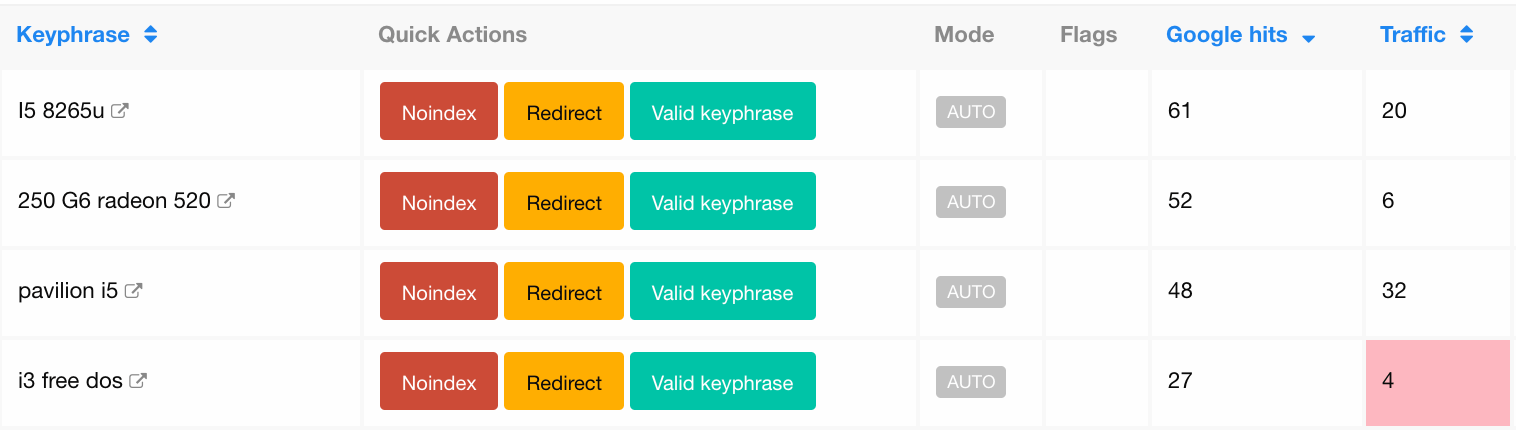
When someone chooses the Redirect action, they are presented with a pop-up so they can choose the redirect targets (maximum 2 Filters + 1 Manufacturer Filter).
Why did we group by keyphrase and not just URLs?
Because the same keyphrase is present in many URL combinations (Filter + Keyphrase), every action we made for one keyphrase could affect dozens of similar URLs with the same keyphrase and save us time.
For example, let’s say that we have these two internal search URLs with the keyphrase >
ultrabookin Laptop Category:
- skroutz.gr/c/25/laptop.html?keyphrase=ultrabook (Keyphrase)
- skroutz.gr/c/25/laptop/m/355/Asus.html?keyphrase=ultrabook (Filter + Keyphrase)
For both URLs, the dashboard would show us
ultrabookas the keyphrase, but we know that Laptop Category has a filter for Ultrabooks.We could select the action Redirect and choose Ultrabook filter as the redirect target. Then the mechanism would redirect the above URLs to the following URLs respectively:
The mechanism gathered an immense amount of keywords, reaching 2.7 millions in total! These 2.7Μ keyphrases where part of 14M indexed URLs (estimated).
After that, our team began to manually curate these keywords starting from the most popular in terms of traffic and crawl hits. Also, our dev team helped with some handy automations like grouping keyphrases with the same product results and handled them all together with one action.
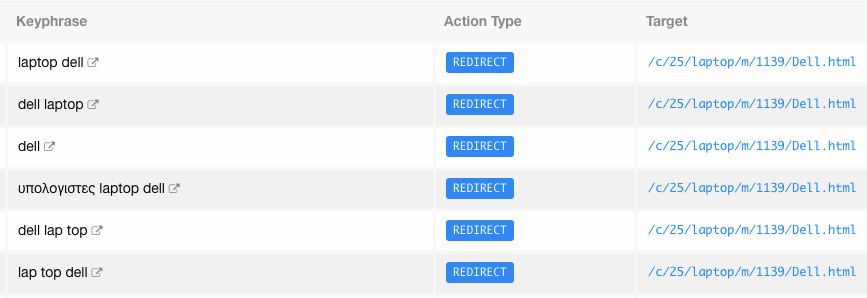 All the above internal search keyphrases had the same number of product results in Laptops Category. As you can see, they are all about Dell Laptops. So, they could be redirected at once in Dell category Filter.
All the above internal search keyphrases had the same number of product results in Laptops Category. As you can see, they are all about Dell Laptops. So, they could be redirected at once in Dell category Filter.
This step helped to curate around 5% of the total keyphrases. The index size decreased in July 2018, from 25M to 21M, but it wasn’t enough.
Along with our manual efforts, we created some automated scripts and mechanisms for redirecting and mostly no-indexing internal search pages. Some of the most important were the following:
- No-index Scripts: We No-indexed all dedicated category search pages:
- with zero organic sessions in the last two months or
- nearly zero organic sessions and up to 3 crawls over the previous 6 months
- Redirect Scripts: We Redirected a dedicated category search page:
- to the category clean URL, if the search (keyphrase) was returning all the products of the category. For example “sneaker” keyphrase was returning 100% of products on “Sneakers” category. So, skroutz.gr/c/3363/sneakers.html?keyphrase=sneakers is redirected to the clean category listing)
- to a specific filter URL, using a script that could linguistically identify combinations of category names with filters or manufacturers just from the keyphrase. For example “stan smith black” query is matching two different filters: “Stan Smith” and “Black”. So, if a user search for “stan smith black” he will redirected to the category page with the two filters enabled.
Note: In the last few months, we are running a more sophisticated mechanism that uses some intelligence from the above linguistic identifier script combined with other factors. The mechanism can decompose every search query, match it’s keyphrases to existing filters and redirect the internal search URL to the specific filter/ filter combination URL.
This mechanism handles a significant number of the daily internal search queries: 120,000 (18%).
When everything was done by the SEO team, manually or automatically, we made a final big step to curate the long tail of the internal search pages. We created a basic SEO training course with Workshops, 1-1 hands-on and Wiki Guides for many of Content Team members. These members could, in turn, help us with the procedure. The SEO team, of course, was always keeping an eye out on this ongoing process.
The sharing of this knowledge has greatly benefited us in many ways. For example, because of human curation for crawl budget optimization, our content teams gained a better view of the things our visitors are searching for, which helped them to create more useful category filters.
In conclusion, after nearly one year of manual and automated curation, we finally curated 2,700,000 keyphrases, which correspond to approximately 14,000,000 URLs!
Specifically, from the 2,700,000 million internal search keyphrases:
- 2,200,000 were no-indexed (don’t expect these to be removed immediately from Google Index. We saw some delays ranging from a few days to a few months)
- 300,000 were redirected to a filter page url or a category clean url
- 200,000 were marked as valid keyphrases
And that was our primary project.
Before we see the results of our efforts, let’s see what else have we done in a few words.
Secondary SEO Project (Optimize Merge/Split Categories and Alert Mechanism)
1. Optimize SEO when merging/splitting categories
While working on our primary project (crawl budget), we also allocated time for some secondary tasks.
The first one was to optimize and automate our procedure when we merged or split categories so that we won’t lose any SEO value and to provide a better user experience.
- By merging categories, we mean the merge of 2 different categories, like “Baby Shampoo” and “Kids Shampoo”, into one
- By splitting categories, we mean the process of dividing one category into two or more categories. For example, “Jackets” category can be divided into Women’s Jackets and Men’s Jackets categories.
All the above result in lots of redirects, so the SEO juice must be “transferred” from the old URLs to the new ones. What we did to optimize the whole procedure was to create an easy to use Merge/Split Tool, so the content team (which is responsible for the products) can easily map the old URLs with the new ones.
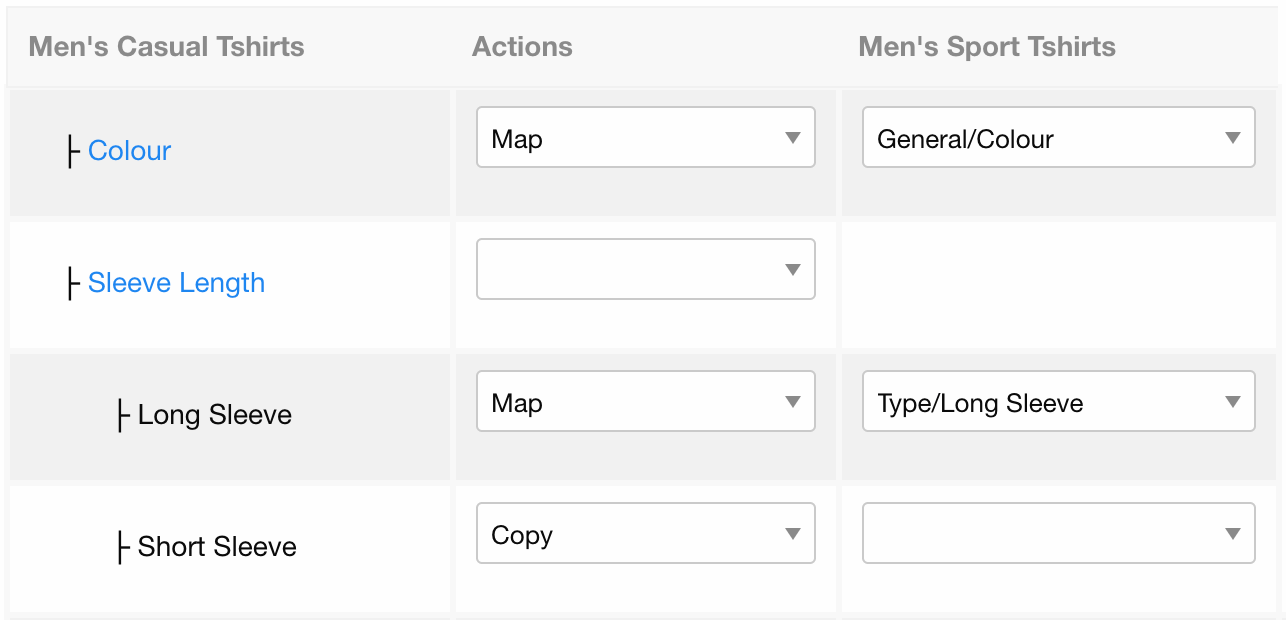 The merge tool shows all the filters from both categories, so the content team can map them or copy them. The mechanism will then use this information to make the redirects automatically.
The merge tool shows all the filters from both categories, so the content team can map them or copy them. The mechanism will then use this information to make the redirects automatically.
2. Create alert mechanism
Alongside Keyphrase Curation, we built a mechanism that sends out notifications to the SEO team, when a critical crawling or indexing issue arises.
How does this mechanism work?
Depending on the alert type, the mechanism sends an alert when a metric (numeric):
- exceeds a specific threshold (for example 20,000 Not Found Pages)
- differs significantly from the normal statistical fluctuation of the last 30 days
As for the tools we use, we have set up alert rules in Grafana Alerting Engine that get delivered to a Slack channel.
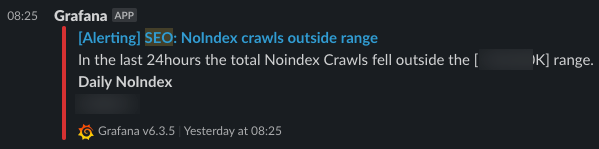
After a notification is received, we use Kibana Monitoring tool to deeper analyze the root of the problem.
Some examples of the alerts we have set:
- Sitemap Differences: Before the daily update of our sitemap files, the mechanism compares each generated file with the already submitted one. If they differ a lot, the alert mechanism informs us and blocks the sitemap submission instantly, until we validate the data
- Noindex Crawls: If crawls of Noindex Pages fall outside of a specified safe range
- Not Found Crawls: If crawls of 404 Pages fall outside of a specified safe range
- Redirect Counts: If crawls of Pages with enabled redirect fall outside of a specified safe range
Part 3: Results
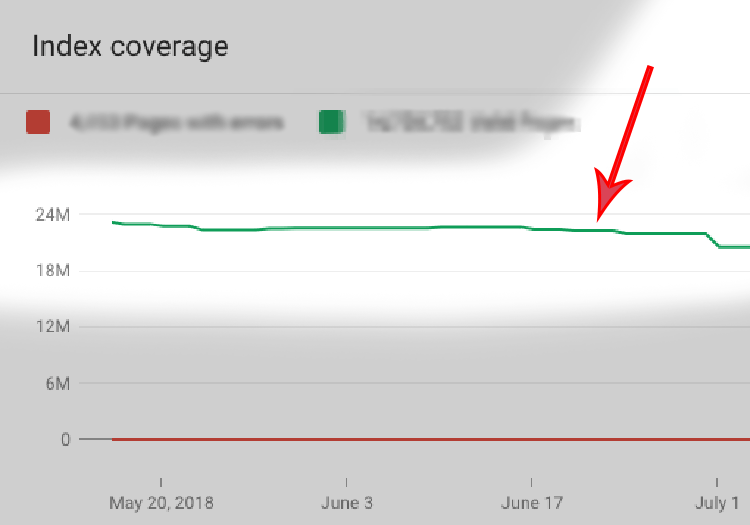
1. Decreased Index Size
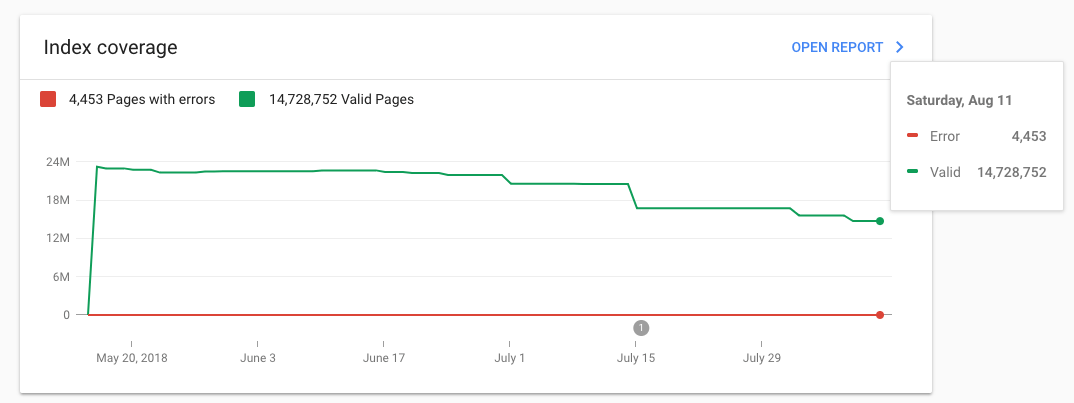
The above graph shows our index size after seven months of hard work and 90% of keyphrases being curated.
As for today?
Even better!
We have now dramatically closed the gap between the actual and expected indexed pages, meaning we reduced the size from 25M to only 7.6M.
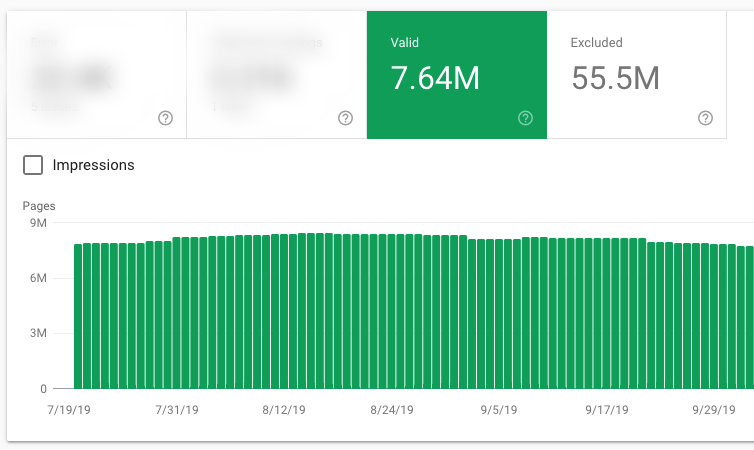
One interesting thing that we observed is this:
GoogleBot doesn’t stop crawling a URL immediately, even if you mark it as no-index. So, if you think that a no-index tag will save your crawl budget instantly, you are wrong.
Notably, we saw that in some cases, GoogleBot returned after 2 or 3 months to crawl a no-index page. We created some metrics for these, and we saw that:
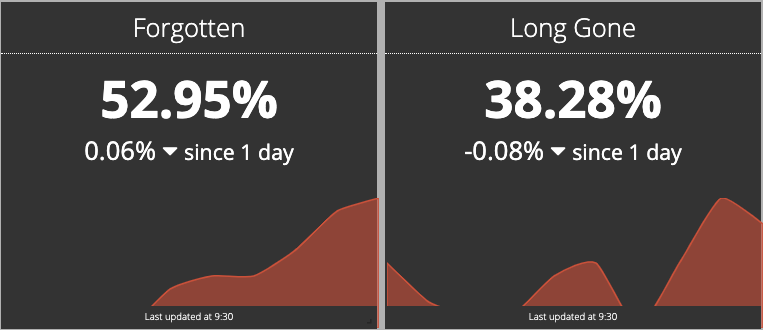
- Only half of our no-index internal search URLs haven’t been crawled for at least three months
- Only, 38.28% of our no-index internal search URLs haven’t been crawled for at least six months
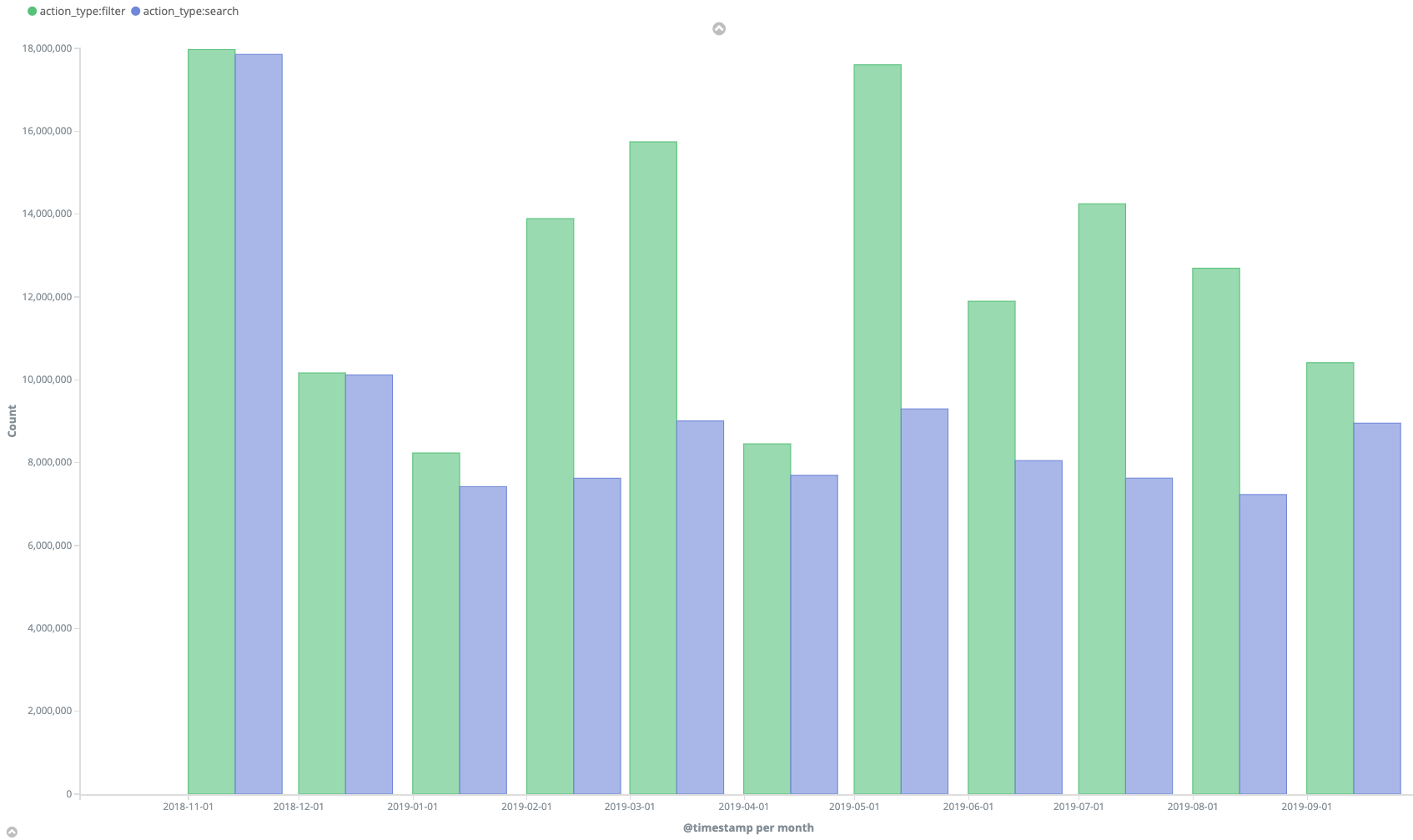
2. Increased Filter Crawl Rate
If we take, for example, the fluctuation of Internal Search Pages Crawls (blue) versus Filter Pages Crawls (green) during the last year, it’s clear that we forced Googlebot to crawl the Filter Pages more frequently than Internal Search Pages.
3. Decreased time for new URLs to be indexed and ranked
Instead of taking 2-3 months to index and rank unique URLs, as we saw in a previous example, indexing and ranking phase now take only a few days.
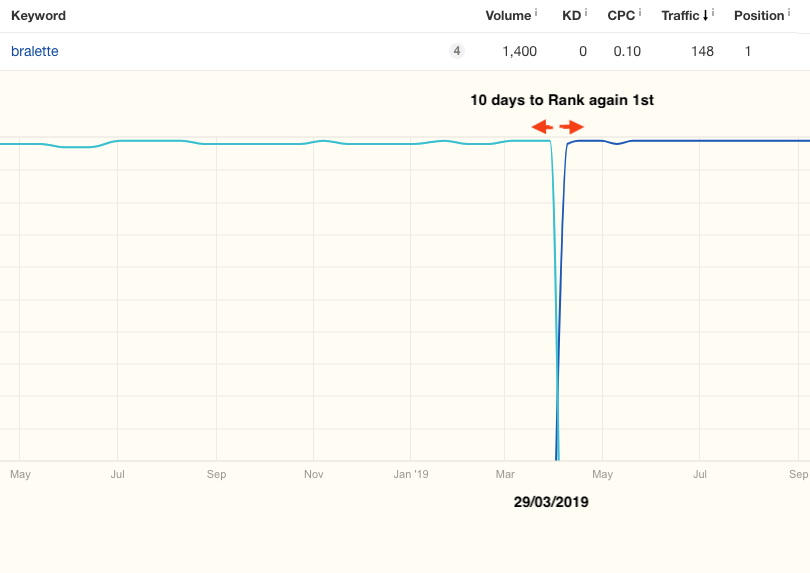 On 29/03/2019, we redirected an internal search page skroutz.gr/c/1487/Soutien.html?keyphrase=bralette to a Category page skroutz.gr/c/3361/Bralettes.html.
On 29/03/2019, we redirected an internal search page skroutz.gr/c/1487/Soutien.html?keyphrase=bralette to a Category page skroutz.gr/c/3361/Bralettes.html.
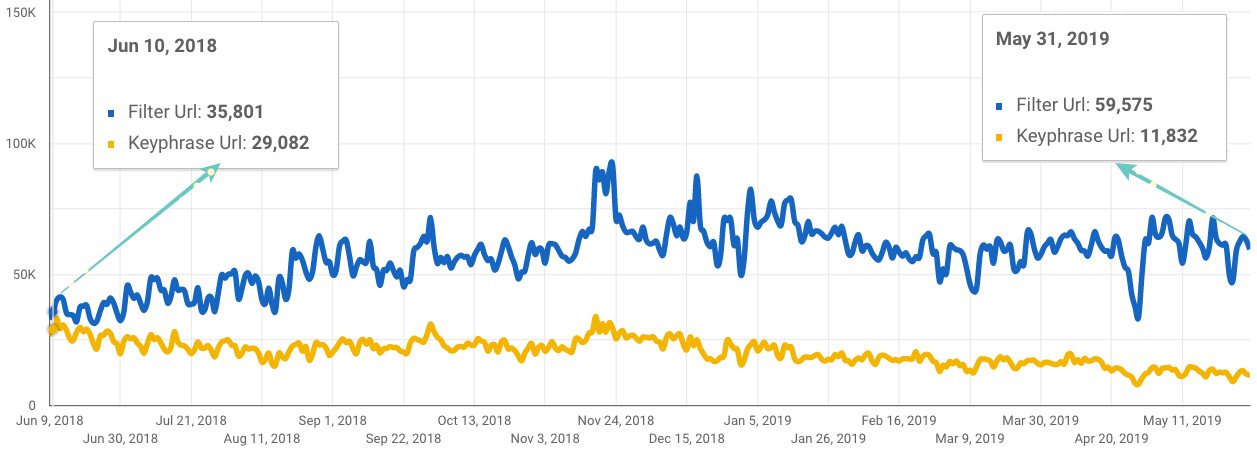
4. Filter URLs have increasing visibility
Take a look at the Data Studio chart below, with data (Clicks) of Search Console from June 2018 to May 2019. You can see how the organic traffic of Filter URLs is increasing compared to the Internal Search Keyphrases URLs traffic, which is slightly decreasing.
5. Average Position Improved, pushing up impressions and clicks
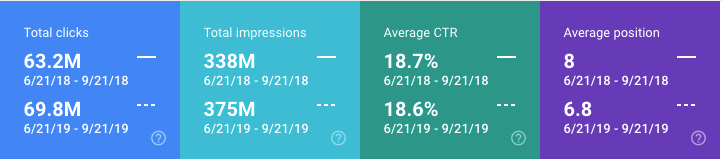 The table from Google Search Console compares the summer of 2018 (exactly when we started the SEO Project) versus the summer of 2019.
The table from Google Search Console compares the summer of 2018 (exactly when we started the SEO Project) versus the summer of 2019.
What We Learned
Over the past two years, we’ve learned a lot during this technical SEO project, and we want to share some things which could eventually help the community.
So here it goes; these are the five most important things we learned:
Takeaway 1:
Crawling monitoring is a must for large sites. You can find insights in such a way you would have never guessed. By monitoring, we don’t necessarily mean real-time like we did. You can also use a website crawler like Jet Octopus or Screaming Frog every month or after a critical change in your site. You would be amazed by the value you could earn by doing this.
An interesting example of other useful insights you can get from crawl monitoring is some critical issues we found when we switched our category listing product pages to React. Without getting into details, after React deployment, GoogleBot started to crawl like crazy no-indexed pages that shouldn’t be crawled, despite being nofollowed from every other link. With crawl monitoring, we were able to immediately see what type of pages had that issue.
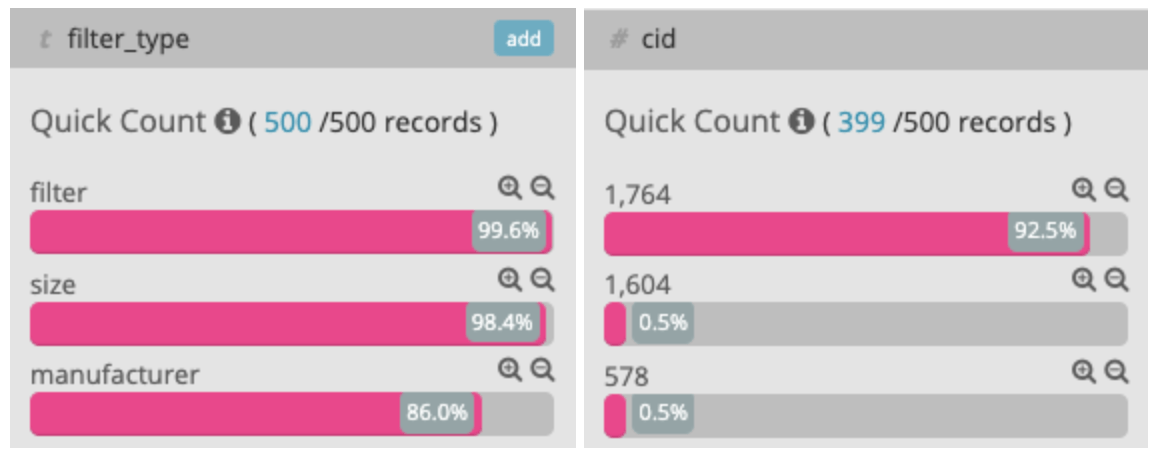
We saw that most of the crawls on no-indexed pages where a combination of size and manufacturer filters on the category with the ID 1764
After all, we found out that GoogleBot executed an inline <script /> and interpreted some relative URL paths as regular URLs, which then crawled at a high rate. We validated this assumption with the addition of a dummy URL in the script, which we later saw that GoogleBot was able to crawl.
Takeaway 2:
Googlebot doesn’t stop crawls immediately after you change a page to no-index. It can take some time. We saw no-indexed URLs to be crawled for months before they have been removed from the Google Index.
Takeaway 3:
Consolidating URLs can backfire easily if not done right. Every URL that is redirected to another must be highly related (nearly duplicate) to each other. We have seen that redirects to irrelevant pages had the opposite results.
Takeaway 4:
Always pay attention when merging or splitting categories. We saw that even if you keep your rankings stable, there might be a delay of up to a few months where you can lose many clicks. Mapping old URLs to new ones and 301 redirects can really help.
Takeaway 5:
SEO is not a one-person show or even one-team show. Sharing of SEO knowledge and cooperation with other teams can empower the entire organization in many ways. For example, Search Team of Skroutz.gr has made a magnificent work by setting-up most of the technical infrastructure of the tools and mechanisms we used on our SEO project.
Finally, you can’t imagine how many SEO issues we have found using feedback from other departments such as Content Teams and Marketing. Even the CEO of Skroutz.gr himself, has helped a lot on technical issues we had (Scripts etc.).
That’s all folks.
Congratulations on getting to the very end of this, quite large :-), case study!
Have you ever used any insights from the crawling behavior of GoogleBot to solve issues on your site? How did you deal with them? Let us know in the comments section below!
Vasilis Giannakouris,
on behalf of Skroutz SEO Team