In the last few years the android team has grown significantly and with that so did our codebase. We are at a state that the lack of documentation has become an issue but not for what you might think. Documenting a class as to how it works is not as essential as making the same class easy to discover!
Couple of our problems:
- The biggest issue we have is the inability to reason as to what we support.
For example, we have a concept called
Section. Each section has its own type and based on that type we render it with a different layout. Being able to see, at a glance, which types we render has become nearly impossible since every relevant component might reside οn a different package or even module. Do we have anything for [place need here]?. This question is being asked a bit too often and its answer depends either on the mnemonic of the rest of the team or on the efficiency of the IDE’s search as long as the name of the function/class etc is descriptive enough.
Our goal
It is clear that we need to have some kind of documentation that will allow us to discover easily what can help us. A documentation that, apart from listing all classes, functions etc, can have custom lists like the one with all of our sections.
So, based on that we decided that we need to:
- Have a way to group code, from different files/packages, together.
- Be able to add a visual hint such as an image (a picture is worth a thousand words).
- Have docs that contain only the code that has comments. Everything else is just a distraction.
Dokka
We decided to use Dokka to achieve our goal. It is a tool written and maintained by Jetbrains and can be extended by a plugins system allowing each team to add the functionality it needs.
Dokka’s flow
In a very abstracted and simplified way we can describe Dokka’s flow like this:

- First, you provide to it anything that can be represented by modules, classes, functions etc. This is the
Input. - That input is being translated to a list of
Documentableswhere each documentable is one of the aforementioned concepts. - The documentables are then transformed to a tree of
Pages(one page per documentable) where each page is a collection of information represented by structures such as titles, texts, links etc. - Finally these pages are being rendered to a desired format such as an HTML or Markdown page. This is the
Output.
Entry points for plugins
You might be wondering where do we write our plugin’s code? For that we need to see the above flow in more details:
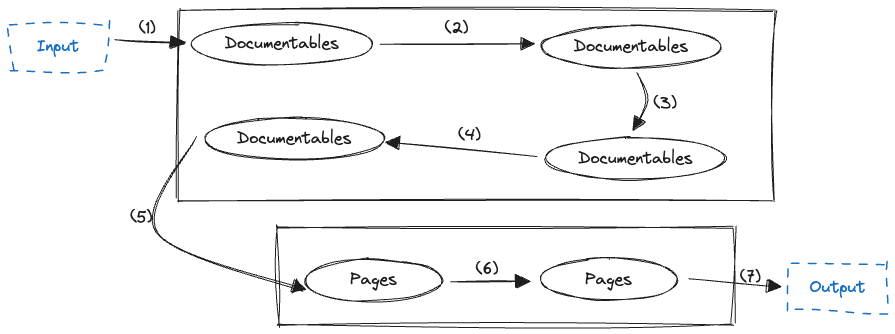
Here, every arrow is an extension point:
- By default Dokka provides a way to translate Java/Kotlin code to documentables but it also allows us to add our own translations too. The resulted documentables are being organized in modules. These are not, necessarily, the modules we have in our project, even though that is the case in an android project.
- At this point Dokka provides us a list of modules and allows us to transform them however we need. We can add, remove, change all kinds of documentables including the list of provided modules.
- Here is where all modules are being merged into one. Dokka expects to have a single merger and provides a default implementation for it. Anything we provide must override the default one.
- Yet another transformation point, like in step 2, only that this time we have a single module with all documentables in it.
- Moving from documentables to pages Dokka expects to have a single translator. Again, it provides a default implementation and anything we provide must override it.
- At this point Dokka provides us with a tree of pages and the ability to add one or more transformations for that tree. We can modify the tree by adding, removing or updating a page.
- The final entry point is where Dokka allows us to provide our own renderer. By default it uses one of its own implementations that renders the tree of pages into HTML pages.
Documentation node
Creating a documentation relies on two things, the code and, of course, the comments.
If a piece of code has a doc-comment, its corresponding documentable will have a documentation node
which is nothing more than a list of TagWrappers.
A TagWrapper is used to represent anything that KDoc supports (the description -both summary and detailed-,
the author, the since tag etc) plus any custom tag that will be used to extend KDoc. This custom tag
is being represented in code by CustomTagWrapper.
Skroutz Dokka Plugin
First steps
We decided to have the plugin as part of our repository.
For that we:
- created a Java/Kotlin library module and made it depend on
org.jetbrains.dokka:dokka-coreandorg.jetbrains.dokka:dokka-base. - created a class that extends
DokkaPluginand - added a file named org.jetbrains.dokka.plugability.DokkaPlugin in the module’s resource folder (src/main/resources) under the path
META-INF/services. The file points to the class we created:gr.skroutz.dokka.plugin.SkzDokkaPlugin.
Now every time we run one of Dokka’s gradle tasks (ex: dokkaHtmlMultiModule) our plugin’s code is being loaded and executed for every module that is configured to create documentation.
Configuring a module:
- Dokka must be added in the
plugins { }section and - Our plugin must be given as a dependency
dokkaPlugin(project(":skroutz-dokka-plugin"))
Have docs that contain only the code that has comments
Even though it was not the first in our list it was the place to start since we did not want the clutter of having many documentables that offer nothing, since they don’t have any comments.
By default Dokka creates a page for every documentable. We didn’t want that. If our documentation has a page it will be because there is a comment in it.
For that we chose to go with entry point #2 and wrote a new PreMergeDocumentableTransformer.
Its job is to filter the provided list of modules and keep only those that have at least one package which, on its turn, has at least one documentable with a comment.
Implementation notes:
- We used
SuppressedByConditionDocumentableFilterTransformerwhich is designed for exactly that. Suppressing a documentable or not:
private class KeepOnlyDocumentablesWithComments(
context: DokkaContext
): SuppressedByConditionDocumentableFilterTransformer(context) {
override fun shouldBeSuppressed(d: Documentable): Boolean {
return d !is DPackage && !d.hasDocumentation()
}
}- We used an extension function for checking if a documentable has comments:
internal fun Documentable.hasDocumentation(): Boolean {
val hasDocumentation = documentation.values.flatMap { it.children }.isNotEmpty()
if (hasDocumentation) return true
return children.any { it.hasDocumentation() }
}and the key part here is the recursion. This supports cases like a class that, on its own, does not have a comment but one of its properties/methods does.
Have a way to group code, from different files/packages, together.
The combination of Dokka and KDoc allows the usage of custom block-tags so we decided to leverage it
for creating groups of code. Each time we want a certain class/function etc to be part of a group
we tag it by using @tags name-of-group in its doc-comment:
/**
* Renders a SKU in the list layout.
*
* @tags section item, rendered sku
*/For that we had to implement yet another PreMergeDocumentableTransformer.
Its job is to
- collect, from all modules, all the documentables that their comment includes our custom block tag
- group them by the tag’s name
- create a package for every group (tag)
- create a module that has all these new packages
internal class CreateTagsModule : PreMergeDocumentableTransformer {
override fun invoke(modules: List<DModule>): List<DModule> {
val allDocumentables = modules
.flatMap { module -> module.packages }
.flatMap { pckg -> pckg.allDocumentables() }
val hasTags = allDocumentables
.any { documentable -> documentable.hasTags() }
val sourceSets = modules.first().sourceSets
return if (hasTags) modules + createTagsModule(allDocumentables, sourceSets) else modules
}
private fun createTagsModule(allDocumentables: List<Documentable>, sourceSets: Set<DokkaConfiguration.DokkaSourceSet>): DModule {
val tagPackages = allDocumentables
.filter { documentable -> documentable.hasTags() }
.flatMap { documentable -> documentable.allTags().map { tag -> tag to documentable } }
.groupBy { entry -> entry.first }
.mapValues { entry -> entry.value.map { it.second } }
.map { entry -> createTagPackage(entry.key, entry.value, sourceSets) }
return DModule(
name = TAGS,
packages = tagPackages,
documentation = emptyMap(),
sourceSets = emptySet()
)
}Implementation notes:
- Dokka does not allow a documentable to be part of more than one pages. This means that simply creating a new package with the tagged documentables would cause a failure. That is why for every new package we made copies of the necessary documentables and add those to it.
private fun Documentable.makeCopyForTag(tag: String): Documentable {
val newDri = dri.copy(extra = tag)
return when (this) {
is DFunction -> copy(dri = newDri, extra = PropertyContainer.withAll(IsCopy))
is DProperty -> copy(dri = newDri, extra = PropertyContainer.withAll(IsCopy))
is DTypeAlias -> copy(dri = newDri, extra = PropertyContainer.withAll(IsCopy))
is DClasslike -> makeCopy(newDri)
is DParameter -> copy(dri = newDri, extra = PropertyContainer.withAll(IsCopy))
else -> throw IllegalStateException("I don't know what to do with $this")
}
}- This transformer is set to run after the one that filters out all documentables with no comments
internal val createTagsModule by extending {
dokkaBase.preMergeDocumentableTransformer with CreateTagsModule() order { after(suppressDocumentablesWithNoDocumentation) }
}Showing tags in the documentable’s page
One thing we wanted was to have our custom tags render in a page just like @since or @author do.
For that Dokka provides an abstraction (CustomTagContentProvider) that you can implement and provide the way you want your
custom tag to be structured.
For our @tags tag we choose to go with a title and the tags underneath it:
override fun PageContentBuilder.DocumentableContentBuilder.contentForDescription(
sourceSet: DokkaConfiguration.DokkaSourceSet,
customTag: CustomTagWrapper
) {
group(sourceSets = setOf(sourceSet), styles = emptySet()) {
header(4, TAGS)
comment(customTag.root)
}
}Making tags searchable
One of the PageTransformers (entry point #6) that Dokka offers out of the box is SearchbarDataInstaller.
Its job is to create the file that populates the search functionality.
We decided to add a descendant of SearchbarDataInstaller and create a search record for every
tag we come across. For that we made sure that when a package related page gets processed we check
if it contains a tag-package documentable and if it does we create a search record for that tag:
override fun processPage(page: PageNode): List<SignatureWithId> {
if (page.isCopy()) return emptyList()
if (page !is PackagePageNode) return super.processPage(page)
val tagPackage = page.documentables.firstOrNull { it is DPackage && it.extra[IsTagPackage] != null }
if (tagPackage != null) {
tagPackageNames.add(page.name)
return page.dri.map { SignatureWithId(it, page) }
}
return super.processPage(page)
}
override fun createSearchRecord(name: String, description: String?, location: String, searchKeys: List<String>): SearchRecord {
if (name !in tagPackageNames) return super.createSearchRecord(name, description, location, searchKeys)
val tag = name.removePrefix(TAG_PACKAGE_PREFIX)
return SearchRecord(
name,
tag,
location,
listOf(tag)
)
}Implementation notes:
- In order to have our transformer executed we had to override the default one
internal val makeTagsSearchable by extending {
dokkaBase.htmlPreprocessors providing ::MakeTagsSearchable override dokkaBase.baseSearchbarDataInstaller
}- Every documentable provides a container where you can add custom properties.
We used that to characterize every copied documentable with the property
IsCopyand every every tag-package withIsTagPackageduring the documentables’ transformations.
internal data object IsCopy : ExtraProperty<Documentable>, ExtraProperty.Key<Documentable, IsCopy> {
override val key: ExtraProperty.Key<Documentable, *> = IsCopy
}
internal class IsTagPackage(val tag: String) : ExtraProperty<DPackage> {
override val key: ExtraProperty.Key<DPackage, *> get() = IsTagPackage
internal companion object : ExtraProperty.Key<DPackage, IsTagPackage>
}This way we where able to keep here only the pages that contained our tags.
Be able to add a visual hint such as an image
Grouping code is very helpful. There are cases though, like the one with sections, that it wasn’t enough. We wanted every group item to have a preview of how it looks so that we can easily pick and choose what fits our needs.
For supporting that we had to break it to two parts:
- First we needed to add support for one more block-tag. One that will be used to provide the name of an image.
- Then we had to make sure that the image is being rendered in the resulted page
The block-tag
We wanted to make it as easy as possible for the commenter:
- Take a screenshot
- Give it the name you want (ex:
image-name.png) - Move it to a specific folder (ex:
images/previews) - Add the block tag
@preview image-name.pngto the comment
/**
* Renders a list of pills horizontally.
*
* @tags section
* @preview section-pills.png
*/ Then, another implementation of CustomTagContentProvider will make sure that the block-tag will be
structured as an image:
private fun PageContentBuilder.DocumentableContentBuilder.previewComment(customTag: CustomTagWrapper) {
val text = (customTag.root.children.first().children.first() as Text)
val customDocTag = CustomDocTag(
children = listOf(
Img(
params = mapOf(
"href" to "images/previews/${text.body}",
"alt" to ALT_SKZ
)
)
),
name = customTag.name
)
comment(customDocTag)
}Rendering the image
The content provider sets the image’s structure but, at this stage, it does not know anything about the page that will use it. So the image’s path is not correct and the page will no be able to find it.
To fix it we wrote a PageTransformer that changes the image’s path after taking into consideration
the page’s position in the tree of pages:
override fun invoke(input: RootPageNode): RootPageNode {
val locationProvider = locationProviderFactory.getLocationProvider(input)
return input.transformContentPagesTree { contentPage ->
val hasPreviewImage = contentPage.content.allContentNodes().any { it is ContentEmbeddedResource && it.altText == ALT_SKZ }
if (hasPreviewImage) {
val count = locationProvider.ancestors(contentPage).count()
return@transformContentPagesTree contentPage.modified(
content = contentPage.content.mapTransform<ContentEmbeddedResource, ContentNode> {
val prefix = "../" * count
it.copy(address = prefix + it.address)
}
)
}
contentPage
}
}Final result
As we already said, an image is worth a thousand words, so this is how our docs are starting to look:
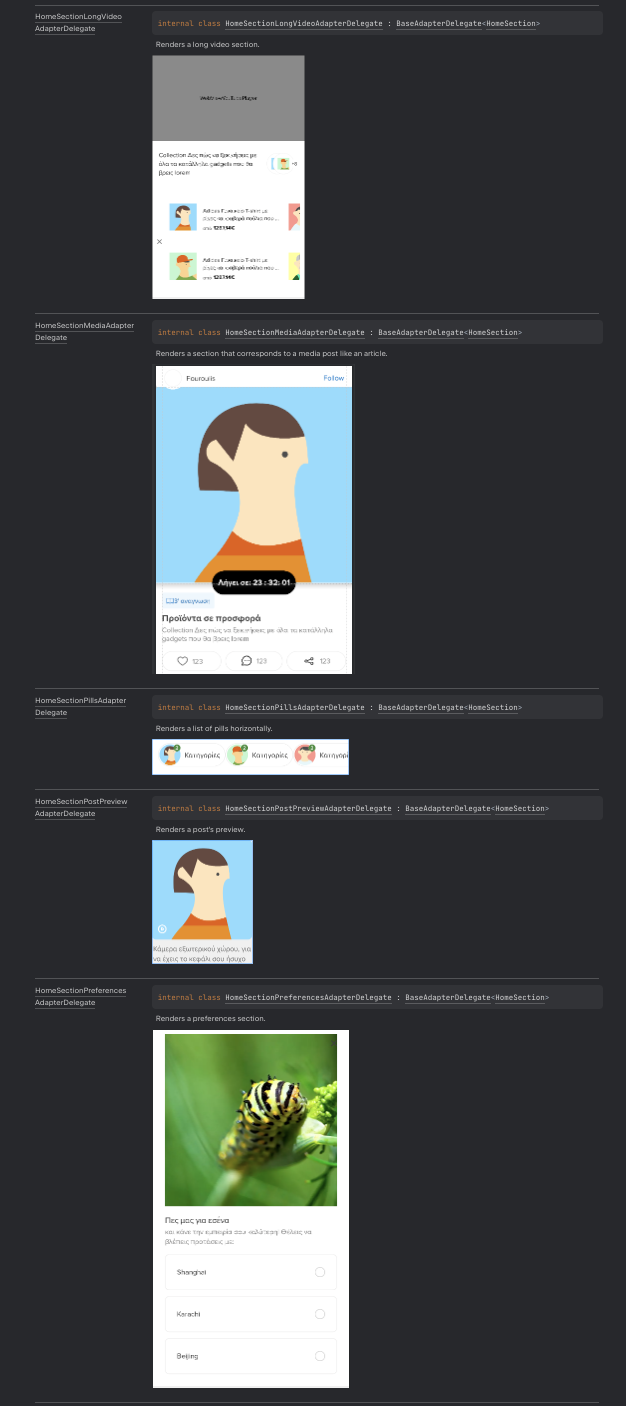 this is the page for the tag
this is the page for the tag section