The Challenge
At Skroutz, we are passionate about our product, and it is always our top priority. We are constantly working to improve and evolve it, supported by a large and talented team of software engineers. Our product’s continuous innovation and evolution lead to frequent updates, often necessitating changes and additions to the schemas of our operational databases.
When we decided to build our own data platform to meet our data needs, such as supporting reporting, business intelligence (BI), and decision-making, the main challenge, and also a strict requirement, was to ensure that it would not block or even delay our product development in any way.
We chose Amazon Redshift to promote data democratization, empowering teams across the organization with seamless access to data, enabling faster insights and more informed decision-making. This choice supports a culture of transparency and collaboration, as data becomes readily available for analysis and innovation across all departments.
However, keeping up with schema changes from our operational databases, while updating the Data Warehouse without constantly coordinating with development teams, delaying releases, or risking data loss—became a new challenge for us.
Overview of the solution
Most of our data resides in our operational databases, such as MariaDB and MongoDB.
Our approach involves using the Change Data Capture (CDC) technique, which automatically
handles the schema evolution of the data stores being captured.
For this, we utilized Debezium along with a Kafka cluster.
This solution enables schema changes to be propagated without disrupting the Kafka consumers.
However, handling schema evolution in Amazon Redshift became a bottleneck, prompting
us to develop a strategy to address this challenge.
It’s important to note that, in our case, changes in our operational databases primarily involve adding new columns rather than breaking changes like altering data types.
Therefore, we have implemented a semi-manual process to resolve this issue, along with a mandatory alerting mechanism to notify us of any schema changes. It is actually a two-step process which breaks down in handling schema evolution in real-time and handling data update in an async manual step.
AWS Services used
Amazon Redshift is a fully managed, petabyte-scale data warehouse service designed to handle large-scale data analytics. It allows users to run complex queries and perform advanced analytics on massive datasets quickly and efficiently. Built on PostgreSQL, Amazon Redshift offers a columnar storage format, which optimizes query performance and reduces storage costs. Its integration with various data visualization tools and support for SQL make it a popular choice for businesses looking to gain insights from their data without the overhead of managing infrastructure.
Architecture walkthrough
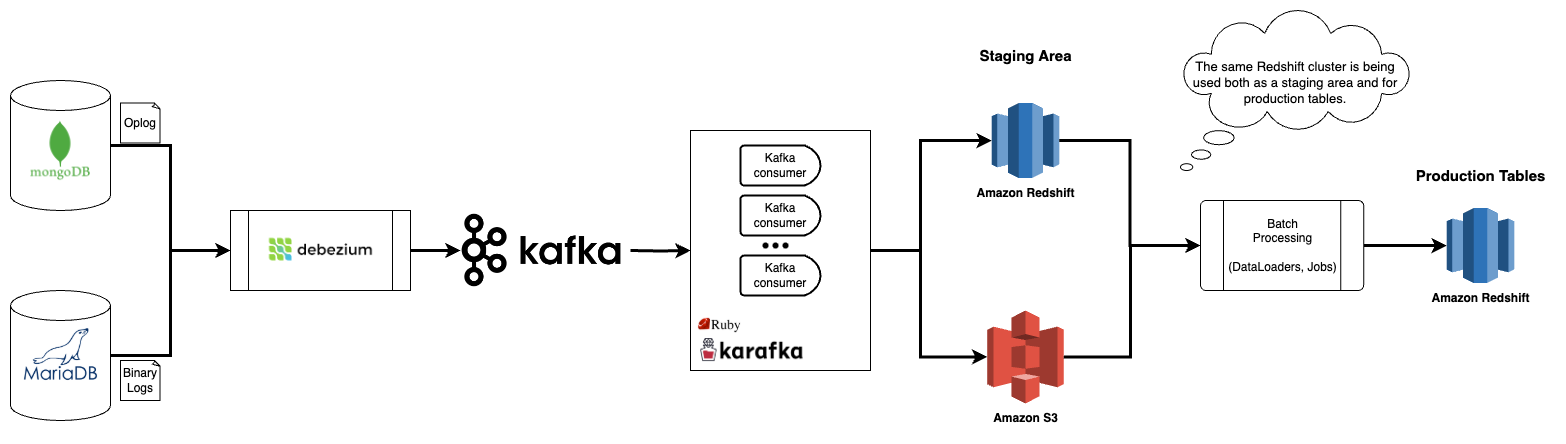
This architectural diagram illustrates a hybrid deployment model, integrating both on-premises and cloud-based components.
The data flow begins with data from MariaDB and MongoDB, captured using Debezium for Change Data Capture (CDC)
in near real-time mode.
The captured data are streamed to Kafka cluster, where Kafka consumers (built on the Ruby Karafka framework)
read and write them to the staging area, either in Amazon Redshift or Amazon S3.
From the staging area, DataLoaders promote the data to production tables in Amazon Redshift.
At this stage, we apply the Slowly Changing Dimension (SCD) concept to these tables, using Type 7 for most of them.
Afterwards, analytical jobs are run to create reporting tables, enabling business intelligence and reporting processes.
As an example of the data modeling process from a staging table to a production table, please refer to the diagram below:
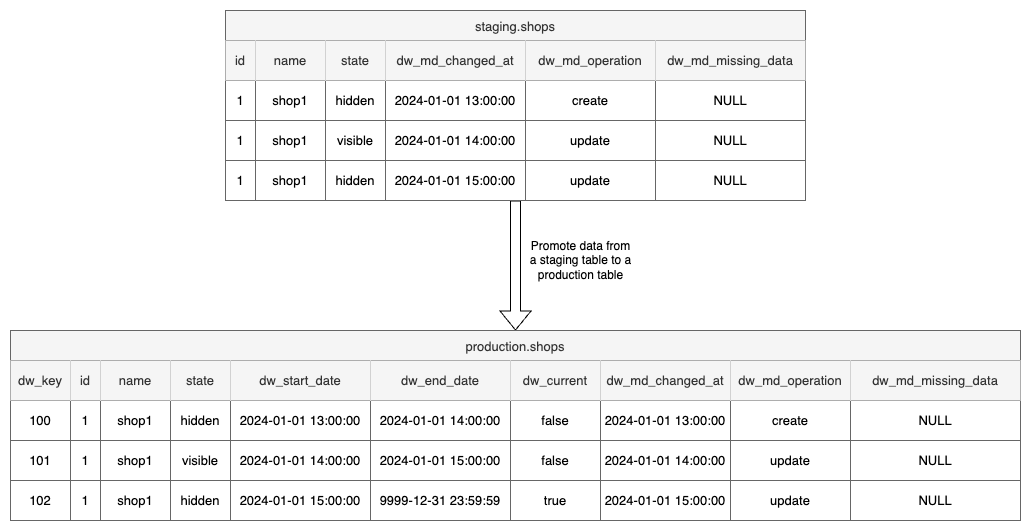
The architecture depicted in the diagram shows only our CDC pipeline which fetches data from our operational databases and does not include other pipelines we have, such as those for fetching data through APIs, scheduled batch processes, and many more.
Also note that our convention is that dw_* columns are used to catch SCD metadata information and other
metadata in general.
Solution Deep Dive
Real-Time Workflow
For the schema evolution part, we will focus on the column dw_md_missing_data, which captures schema
evolution changes in near real-time that occur in the source databases.
When a new change is produced to Kafka cluster, the Kafka Consumer is responsible for writing this change to the staging table in Amazon Redshift.
For example, a message produced by Debezium to Kafka cluster will have the following structure when a new shop entity is created:
{
"before": null,
"after": {
"id": 1,
"name": "shop1",
"state": "hidden"
},
"source": {
...
"ts_ms": "1704114000000",
...
},
"op": "c",
...
}
The Kafka consumer is responsible for preparing and executing the SQL INSERT statement:
INSERT INTO staging.shops (
id,
"name",
state,
dw_md_changed_at,
dw_md_operation,
dw_md_missing_data
)
VALUES
(
1,
'shop1',
'hidden',
'2024-01-01 13:00:00',
'create',
NULL
)
;
After that, let’s say a new column is added to the source table called “new_column”, with the value “new_value”.
The new message produced to Kafka cluster will have the following format:
{
"before": { ... },
"after": {
"id": 1,
"name": "shop1",
"state": "hidden",
"new_column": "new_value"
},
"source": {
...
"ts_ms": "1704121200000"
...
},
"op": "u"
...
}
Now the SQL INSERT statement executed by the Kafka consumer will be:
INSERT INTO staging.shops (
id,
"name",
state,
dw_md_changed_at,
dw_md_operation,
dw_md_missing_data
)
VALUES
(
1,
'shop1',
'hidden',
'2024-01-01 15:00:00',
'update',
JSON_PARSE('{"new_column": "new_value"}') /* <-- check this */
)
;
The consumer performs an INSERT as it would for the known schema, and anything new is added to
the dw_md_missing_data column as key-value JSON.
Once the data is promoted from the staging table to the production table, it will have the following structure:
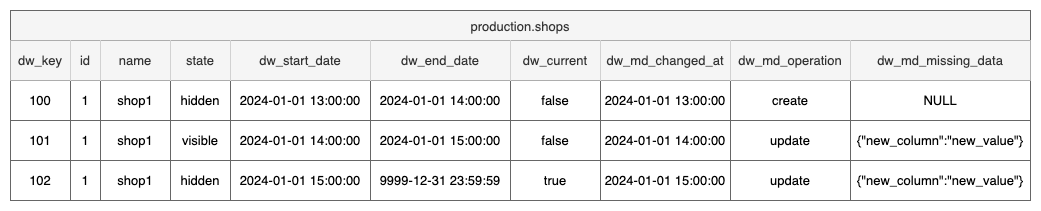
At this point, the data flow continues running without any data loss or the need for communication with teams responsible for maintaining the schema in the operational databases. However, this data may not be easily accessible for the data consumers, analysts etc.
It’s worth noting that dw_md_missing_data is defined as a column of the SUPER data type,
which was introduced in Amazon Redshift to store semistructured data or documents as values.
Monitoring Mechanism
To track new columns added to a table, we have a scheduled process that runs weekly.
This process checks for tables in Amazon Redshift with values in the dw_md_missing_data column
and generates a list of tables requiring manual action to make these data available through
a structured schema. A notification is then sent to the team.
Manual Remediation Steps
In the aforementioned example, the manual steps in order to make this column available would be:
Step 1: Add the new columns to both staging and production tables
ALTER TABLE staging.shops ADD COLUMN new_column varchar(255);
ALTER TABLE production.shops ADD COLUMN new_column varchar(255);
Step 2: Update Kafka consumers known schema
In this step we just need to add the new column name to a simple Array list.
e.g
class ShopsConsumer < ApplicationConsumer
SOURCE_COLUMNS = [
'id',
'name',
'state',
'new_column' # this one is the new column
]
def consume
# Ruby code for:
# 1. data cleaning
# 2. data transformation
# 3. preparation of the SQL INSERT statement
RedshiftClient.conn.exec <<~SQL
/*
generated SQL INSERT statement
*/
SQL
end
end
Step 3: Update DataLoader’s SQL logic for the new column
A DataLoader is responsible for promoting the data from the staging area to the production table.
class DataLoader::ShopsTable < DataLoader::Base
class << self
def load
RedshiftClient.conn.exec <<~SQL
CREATE TABLE staging.shops_new (LIKE staging.shops);
SQL
RedshiftClient.conn.exec <<~SQL
/*
We move the data to a new table because in staging.shops
the Kafka consumer will continue add new rows
*/
ALTER TABLE staging.shops_new APPEND FROM staging.shops;
SQL
RedshiftClient.conn.exec <<~SQL
BEGIN;
/*
SQL to handle
* data deduplications etc
* more transformations
* all the necessary operations in order to apply the data modeling we need for this table
*/
INSERT INTO production.shops (
id,
name,
state,
new_column, /* --> this one is the new column <-- */
dw_start_date,
dw_end_date,
dw_current,
dw_md_changed_at,
dw_md_operation,
dw_md_missing_data
)
SELECT
id,
name,
state,
new_column, /* --> this one is the new column <-- */
/*
here is the logic to apply the data modeling (type 1,2,3,4...7)
*/
FROM
staging.shops_new
;
DROP TABLE staging.shops_new;
END TRANSACTION;
SQL
end
end
end
Step 4: Transfer the data that has been loaded in the meantime from the dw_md_missing_data super column to the newly
added column and then clean up.
In this step we just need to run a data migration like the following:
BEGIN;
/*
Transfer the data from the `dw_md_missing_data` to the corresponding column
*/
UPDATE production.shops
SET new_column = dw_md_missing_data.new_column::varchar(255)
WHERE dw_md_missing_data.new_column IS NOT NULL;
/*
Clean up dw_md_missing_data column
*/
UPDATE production.shops
SET dw_md_missing_data = NULL
WHERE dw_md_missing_data IS NOT NULL;
END TRANSACTION;
In order to perform the above operations we make sure that no one else performs changes
to the “production.shops” table as we want to guarantee that no new data will
be added to the dw_md_missing_data column.
Future Improvements
As the migration of Skroutz to the AWS cloud approaches, discussions are underway on how the current architecture can be adapted to align more closely with AWS-native principles. To that end, one of the changes considered are Amazon Redshift streaming ingestion from MSK or Open Source Kafka which will allow Skroutz to process large volumes of streaming data from multiple sources with low latency and high throughput to derive insights in seconds.
Links:
Written in collaboration with Konstantina Mavrodimitraki (LinkedIn profile), Senior Solutions Architect @ AWS. Thank you for your contributions!