Skroutz is a marketplace that hosts more than 8,500 merchants and keeps adding 500 new merchants per month. This translates to more than 80,000 new offers per day with peaks as high as 200,000 on certain occasions.
Our product content team is one of the largest in the organization (140 people as of Mar 2021) but to be able to handle high product loads we had to implement a number of automation tools for product classification.
Merchants have two ways of uploading products to Skroutz:
- Via an XML file that always reflects the merchant’s up to date offers including new ones
- Through our merchants CMS (used by merchants without a platform of their own)
When a new offer (or a product in the Skroutz jargon) is detected, it is identified and if possible placed in the appropriate category and merged into the corresponding SKU.
Before we move on to describe how the classification is achieved it is important to describe some of the basics:
- An SKU is a brand’s unique product that is uniquely described by a part number or an EAN.
- An offer is unique to a merchant but generally describes an SKU. The offer should in reality carry all the necessary attributes of the SKU so that it can be correctly identified but, unfortunately, that’s rarely the case.
- A category represents a class of SKUs (e.g. smartphones, sneakers). Merchants and Skroutz almost always have a different categorization hierarchy. Our category tree has many levels but only leaves contain SKUs, top level categories are there to help consumers navigate.
- SKUs have specifications in a structured format that can be used by consumers to filter results. E.g. a smartphone will have a screen size specification whereas a dress will have a color specification. These specifications are defined on a category level.
- An SKU belongs to a brand or a manufacturer (e.g. Samsung)
The above relations are better depicted in the diagram below:
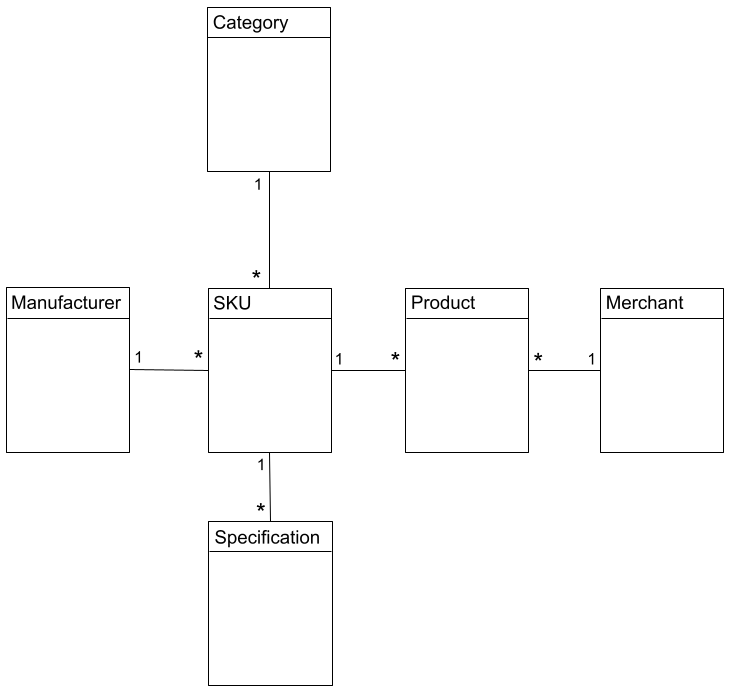
On average, 60% of all incoming products/offers belong to an existing SKU. Ideally, the SKU part numbers or EAN should be enough for SKU classification but in reality those attributes are often either missing or are just plain wrong.
Classification
Our classification tool goes by the name of Tron with two major subtools:
- Megatron: classifies incoming products to categories using machine learning
- Ngntron (or new generation tron): classifies products into SKUs using feature extraction
The purpose of this post is to describe Ngntron and how feature analysis has helped us build a myriad of satellite tools other than just classification.
SKU classification
Incoming products are plain text representations of their attributes, with all their necessary attributes included like brand name, color, size, etc.
Below are example of those products from various categories:
Xiaomi Poco X3 Dual Sim 6.67" 6GB/128GB 4G NFC Γκρι M2007J20CG
LG Ψυγειοκαταψύκτης GBP62DSNFN (384lt, A+++) Total No Frost
Γυναικεία Παπούτσια Vans | Old Skool Platform Black | Womens Shoes Black VN0A3B3UY281
As evident from the examples above, product descriptions follow no standard pattern and in some cases include marketing information not relevant to the product such as special discounts. Below are the most common problems found in product descriptions:
- Part numbers or EANs can refer to product families (e.g. Apple iPhone 12) and not specific variants (e.g. Apple iPhone 12 64GB Black)
- Random strings instead of part numbers
- Missing or partial information
- Country or region specific part numbers / EANs
- Multiple part numbers
- Redundant or irrelevant information
Our first approach in using plain TF-IDF yielded poor performance. After all our purpose was not to rank products based on relevance but find that one true perfect match or just determine that this is a new product that matches none of the existing.
Feature extraction
The process of feature extraction aims to identify specific attributes in the text representation of the product and tag them or even better link them to known models.
For example, the first product in the list above yields the following results:
product_name = 'Xiaomi Poco X3 Dual Sim 6.67" 6GB/128GB 4G NFC Γκρι M2007J20CG'
analyzer = Ngntron::Analyzers::ProductAnalyzer.new(product_name)
puts analyzer.phraseThe above snippet yields the following results:
[manufacturer] 0,0 => Xiaomi
[model] 1,2 => Poco X3
[filter] 3,4 => Dual Sim
[feature] 3,3 => Dual
[feature] 5,5 => 6.67"
[] 6,6 => 6GB/128GB
[feature] 7,7 => 4G
[filter, feature] 8,8 => NFC
[filter, feature, color] 9,9 => Γκρι
[] 10,10 => M2007J20CG
[pn] 11,11 => 30371
Each identified word in the original phrase has been tagged with one or more tags that correspond to a specific attribute. Similarly:
product_name = 'Γυναικεία Παπούτσια Vans | Old Skool Platform Black | Womens Shoes Black VN0A3B3UY281'
analyzer = Ngntron::Analyzers::ProductAnalyzer.new(product_name)
puts analyzer.phrase[filter, feature] 0,0 => Γυναικεία
[category] 1,1 => Παπούτσια
[manufacturer] 2,2 => Vans
[filter, feature] 3,4 => Old Skool
[model] 5,5 => Platform
[filter, feature, color] 6,6 (9, 9) => Black
[] 7,7 => Womens
[category] 8,8 => Shoes
[pn] 10,10 => VN0A3B3UY281
Each tag contains relevant information as to how it was identified and
what model it is referencing. For example the tag manufacturer would
have the manufacturer id that it matched.
The analyzer employees various heuristics and tricks to make sure that all tags are identified such as aliases (Western Digital vs WD, Call of Duty vs COD), years (2008 vs 08), numbers (IV vs 4) and the list goes on.
Feature comparison
When a new product arrives, its analysis is stored in a serialized format and updated every time the product is changed.
After the category classification has ended the SKU classification takes place by retrieving the product’s analysis and comparing it with existing SKUs.
Based on some predefined strategies such as absolute high entropy PN matchthe
comparison phase will yield a match with a certain confidence level. We
have 3 confidence levels:
- Auto: the product is classified with no human intervention
- Semi-Auto: the product is classified but a human must confirm at some point
- Manual: a human will approve this classification but until then the new product is not classified
Stats
As of today, more than 45% of incoming products that belong to existing SKUs are classified with no human intervention, another 40% is classified but requires approval, and 10% is classified after a human approves the match. Only 5% of new products escape Ngntron and require a human to look for a match.
With the help of Ngntron, merchants with thousands of products can go live with more than 90% of their product catalog listed on Skroutz in just an hour.
Other uses
We use Ngntron’s feature extraction capabilities not just for classification but for other cases as well. Our internal project QuLA will use the same pipeline to determine if an XML feed is suitable for Skroutz in advance and advise the account team accordingly.
We also use extracted features to guide the content team when retroactively adding specifications to a category.
Scaling
Since we expect to reach 20,000 merchants and 250,000 products per day in the near future, classification automation is one of the most important and high impact processes in Skroutz.
We have already tweaked the algorithm to learn from past classifications and adapt its category based confidence levels. In some categories, more than 90% of products are auto classified, greatly reducing the load of the content team and thus enabling us to scale our merchant base.
Of course even 5% of manual classification on such a scale is a huge load and that’s why the content engineering team is already optimizing Ngntron to further reduce the amount of manual work.
Oh and by they way, they are hiring
If you enjoyed reading this post and are curious to learn how Ngntron and other tools in Skroutz work, checkout our open positions