Integrating fuzzy suggestions in a manner that makes sense
Intro
Our Fuzzy Otto project is all about improving the autocomplete functionality of our search field, by providing suggestions for mistyped keyphrases.
The autocomplete functionality of Skroutz’s main search field is probably the first interaction a user has with our web app.
About 22% of all searches in Skroutz come straight from the autocomplete box and even more originally begin as autocompletes and continue with further refinements.
We hope to further increase its usage in the future.
Auto completion contributes to a pleasant user experience
[1] by
(hopefully) reducing the amount of characters one needs to type
before they can execute a search action - particularly so for
keyphrases we know to be popular.
Its importance is even greater for mobile and touch devices where
typing is typically slower, harder and also more error-prone.
Autocomplete is available in Skroutz.gr, Alve.com, Scrooge.co.uk.

Our previous autocomplete implementation had proved its worth.
It was helpful, fast and could employ advanced scoring based
on the search context.
However successful, this functionality was sensitive to typing errors.
With our new mechanism we aimed to build on
the previous approach and extend it with a sensible fall-back
mechanism when (a limited number of) characters are mistyped.
This post will try to demonstrate our experience with the implementation of the new autocomplete system by explaining its requirements, general rationale, building blocks and trade-offs. It will also briefly touch on the custom experimental process we devised in order to evaluate it as well as the results we obtained.
Previous implementation
First of all, it should be noted that we (and our users) were quite
happy with our autosuggestion mechanism to begin with.
It was built around an edge n-grams approach
([2], [3]) that was standard practice a few
years ago and had been proved fast and reliable.
The generated suggestions were (and still are) based on user
data gathered during the last 10 days.
An advanced scoring strategy for reordering suggestions from within
a category was also in place.
That was all fine and well, until you mistyped a single letter.
Then it would just give up alltogether.
Requirements / Goals
Our goal was to develop an approach
that would ‘survive’ 1 or 2 mistyped characters.
Simply searching our existing keyphrase index with a
fuzzy query
was something we were reluctant to do, due to its performance
implications, but fuzziness would definitely be part of the picture.
We also targeted a rather specific functionality that is hard to imagine if you have never used alternative locales on your keyboard: language mapped suggestions
It’s common for people with non-US/UK layouts to write non-English
words (Greek in the case of Skroutz and Turkish in the
case of Alve) by using Latin characters.
This can happen by - intentionally or accidentally - typing a
non-English word using Latin characters.
In short, it’s a process that can turn e.g the Greek word ‘ωμέγα’
into it’s English form: ‘omega’.
(A more thorough explanation of language mapping can be found in
Appendix 1.)
ElasticSearch Completion Suggester
As mentioned before, here in Skroutz, we heavily rely on Elasticsearch for much of our infrastructure needs and especially for anything search or analysis-related It follows that when we first investigated this feature, ES was the first place we turned to. The ES team in the time after our last take on autocomplete had implemented a shiny new, fast mechanism to do just that, but more effectively than the previous (edge n-grams) approach:
Completion Suggesters
are special-purpose index fields, designed specifically with autocompletion in mind.
They are implemented by an in-memory state-machine called
a Finite State Transducer (FST).
And what do you know: they natively support fuzziness.
The ElasticSearch team has wrote an informative blog post explaining what Completion Suggesters can do.
The main reason one would not use such an approach would be if
they needed to index and query a ‘big’ index, in which case an
in-memory data structure is out of the question.
In our domain however, the search terms of a price comparison engine (at least
within the scope of 1-2 weeks) turn out to be relatively modest in size (~100K lines).
Another reason to avoid Completion Suggesters is that the current
implementation (basically) does not support deletions
(see Appendix 2).
In short, there are three things ES’s Completion Suggesters can do for us:
- Given an input text (keyphrase), they can search for prefix matches
in the
inputparameter of the completion field, and sort the results by popularity. - The same entry can have multiple
inputparameters, therefore matching prefixes for each of them. - Prefix matching supports tunable (and automatic) fuzziness.
This figure shows how the matching process works when a user starts typing 'omig':

The completion field shown above can match (and suggest results for)
‘ω’, ‘ωμ’, ‘ωμε’, ‘ο’, ‘om’, ‘ome’, etc.
This is before you specify a fuzziness value in the query.
For a fuzziness of 1, it can match all prefixes that have a
Levenshtein distance
of 1 or less (like 'omig') and so on.
Further customization regarding the matching process is possible
but, for brevity, we refer the interested reader to
the docs.
Blending in Fuzzy results (& keeping it sane)
By leveraging the available functionality of ES, we were able to very
quickly produce a working prototype that could return
fuzzy results for a given keyphrase.
At first glance, it seemed to be just what we wanted. We were able to
get results despite small typos, even for a different language.
Only thing, the results themselves were rather baffling.
It seemed that popular non-exact matches were preferred over (less
popular) exact ones.
Further experimentation revealed this behavior to be ‘unreasonable’
under the circumstances.
As it turns out, for a completion field, ES not inherently
prioritize between fuzzy and non-fuzzy prefix matches - it just sorts
the result set by popularity as a whole.
Returning to our example: 'ωμεγα' would also match 'omg' with
a fuzziness of 1 and 'amiga' with a fuzziness of 2.
If 'omg' and 'amiga' have a popularity higher than 42, then they will
be displayed first, despite their distance or the fact that they are
of a different language.
Potentially, this behavior could prove to be ‘weird’ and unintuitive since
correctly typed searches would not yield the expected (exact) matches.
Avoiding this awkward user experience and offering a more sane approach
was not hard.
A workaround was devised by accepting a small tradeoff on index sizes.
Document-based datastores, like ES, can be used quite differently than
traditional Relational DBs.
It’s not uncommon for duplicate information to exist, even within the same
index (Normal Forms are not at play here).
We just used two completion fields instead of one and populated the second
one with multiple (language mapped) inputs while keeping only the
original keyphrase on the first one.
It turns out you can perform multiple ‘suggest’ queries to ES within the
same request - so that’s what we did, for both fields, querying the
first one without fuzziness.
On aggregating the results, we display the non-fuzzy, same-language
results first and, if they are less than 10, complete the list with the
fuzzy ones.
Here is how it looks in practice:
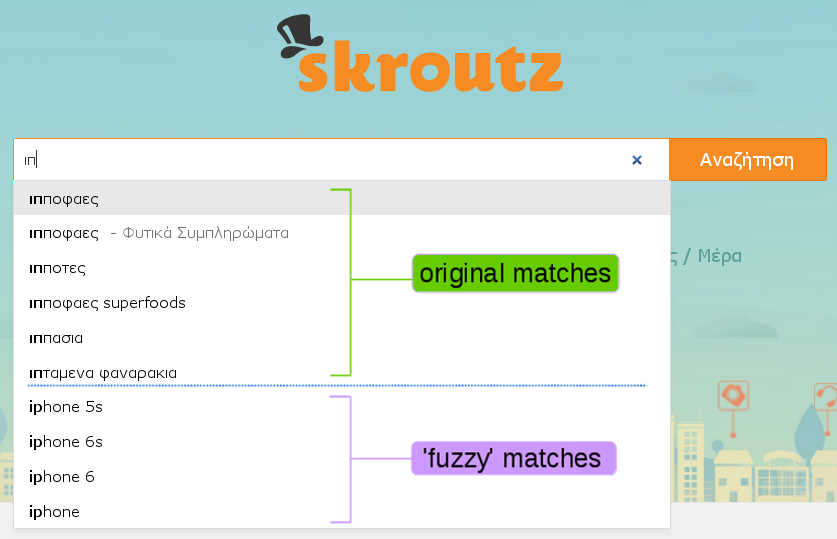
An assumption we made was that the first character of the input is never
mistyped.
We also choose a custom fuzziness factor according to the length of the
input keyphrase ("fuzziness": "auto" does not seem to work well with
UTF-8 input, at least in our version of ES).
We also limit the usage of the language mapping technique to the upper
70th percentile of most popular keyphrases.
This approach ultimately provided a very clean extension on our previous
implementation.
It only intervenes in cases when the previous approach would just not work.
(It’s just a tad slower…)
Tradeoffs and Limitations
As explained, functionally, ‘Fuzzy Otto’ reached our goals.
It:
- allows fuzzy matches (and adapts fuzziness relatively to the keyphrase’s length)
- incorporates language-mapped results (for popular keyphrases only)
- cleanly extends the previous functionality and
- keeps things sane
On that aspect, from a UX standpoint, it represents a clear step forward.
However, like most good things, it comes at a price.
There are roughly 3 things we traded off for using it.
Most importantly (from the author’s perspective) the
autocompletion mechanism became arguably more complex programmatically,
while producing less straight-forward results.
Understanding the indexing and lookup processes now needs more internal
documentation and more involvement.
Moreover, arguing about the correctness of results is less trivial: one needs
to examine Levenshtein distances, popularity data and keyboard mappings
in order to decide whether we were ‘right’ to suggest something or not.
Secondly, the process became slower.
If the performance regression was significant, this could have been a major
showstopper since the autocomplete functionality is arguably the most
latency-sensitive functionality of a web app.
For non-cached results we noticed a measurable regression in performance.
This is attributed to the fact that on each Elasticsearch request we now ask
for two things instead of one.
Processing from the ES side thus takes longer, but that has a possibly less
significant impact than the simple fact that the response is double in size
and incurs a longer transfer time.
However, even on the worst scenarios, the process averages on ~1ms
on the back-end side - merely a fraction of the total end-to-end, user-side
latency.
More importantly, the lookup process is avoided for the vast majority of requests
since these results are cached on both the HTTP Request and Application levels.
Lastly, the index used for the autosuggestion got 3 times bigger and now contains a lot of duplicate information. Its memory footprint has also significantly increased since the ElasticSearch’ s completion functionality is backed by an in-memory data structure. For now, these overheads are non-issues, since our infrastructure can easily handle order-of-magnitude larger indices.
On deletions: the current completion suggester implementation has a very limiting approach on deletions, see Appendix 2.
Evaluation
We try to evaluate any client-facing feature using a control group. An A/B testing methodology is our GOTO approach ( hey, there’s a gem for that) but it’s not always applicable.
In cases like this it’s not rare that we design custom experiments that can offer us an overview of the impact of a feature.
For ‘Fuzzy Otto’, we exposed the feature to 50% of our users for 5 days.
Users that participated in the control group saw the original (non-fuzzy)
approach.
The requests of those participating in the evaluation group were tagged
accordingly for server-side logging.
The autocomplete results that were the products of a fuzzy match (aka.
the user had not typed an exact substring of the suggestion) were also
tagged.
In those cases the exact string that user typed was kept and logged.
At the end of the experiment we could come to the following conclusions:
By examining the requests of users that participated in the experiment we
could calculate the amount of users that had actually selected the product
of a fuzzy match.
It turns out that, in this group, a little more than 10% of the requests coming
from autocomplete targets came from fuzzy suggestions.
Most of those results came from queries typed in the wrong language and
the rest of them comprised of brand-name and product-name typos
(like ‘sumsung’, 'huwei', etc) and misc. typos.
Appendix 1: Language Mapping
In general, language mapping is a practical ‘rule of thumb’ practice that we
use for searching keyphrases that were meant, or should have
been, typed on another language than they actually have been.
Case in study: searching for an ‘omega-3’ food supplement.
Most all such products are indexed with the Latin representation of the word.
However, it’s highly probable that a Greek user searches for 'ωμεγα',
because they chose to type the Greek word, or even 'oμεγα' because
they forgot their keyboard on a GR layout (or just made a typo).
It can also happen vise-versa: writing Greek words with Latin
characters.
This case is particularly common among Greek and Turkish typists: they
try to intentionally capture the phonetic ‘sound’ of a word in Greek or
Turkish in Latin text.
Capturing this behaviour is a little more involved process (more
advanced than just mapping single characters from alphabet A to B)
but it’s handled in a similar manner.
E.g. in the case of 'ωμεγα', simply mapping the Greek characters to
their keyboard-equivalent English ones, yields 'vmega', while
its phonetic representation is 'omega' (and this gets more complicated
for characters like 'Θ' - theta, 'Φ' - phi, etc., that have a phonetic
mapping of multiple Latin characters)
Appendix 2: Suggestion Deletions
A crucial limitation of ElasticSearch’s implementation of completion
suggesters concerns how suggestions are updated or deleted.
Real or near-realtime (or even near-some-time-in-the-future) deletion
or update is not supported.
This type of field must be avoided for scenarios where the index
should be updated when live.
This limitation has been an issue for some time [7] but is
about to be addressed
in the next major version of ES, v5
(and also in Lucene).
References
- Context-sensitive query auto-completion (Paper):
Bar-Yossef, Ziv, and Naama Kraus. “Context-sensitive query auto-completion.” Proceedings of the 20th international conference on World wide web. ACM, 2011.
- Index-Time Search-as-You-Type (ES documentation) </a>
- Edge NGram Tokenizer (ES documentation) </a>
- Working with the ELK Stack at Skroutz </a>
- Skroutz infrastructure at a glance </a>