Introduction
For a while now we needed a solution for distributed stream processing and messaging. Apache Kafka seemed like a solid foundation upon which we could build business-critical applications. Possible use cases include product updates pipelines, order tracking, real-time user notifications, merchant billing and more.
This is the story of how we introduced Kafka to a large monolithic Rails codebase. We will go through the technical details, challenges we faced and decisions we made in the process.
Note: Some familiarity with basic Kafka concepts is assumed.
The challenges ahead
An initial issue stemmed from the fact that Kafka provides relatively low-level abstractions. While this has certain advantages, it also means that authors of client libraries are exposed to a large API surface area and have to get many things right, which makes writing a solid client implementation a demanding task.
Being mostly a Ruby-based organization, we tried different Kafka client libraries written in Ruby but constantly faced hard-to-diagnose bugs. Ruby lacking concurrency primitives makes writing an efficient client a non-trivial task.
We sidestepped these problems by following a different route: hide the low-level complexities in a standalone service that exposes a minimal API for clients to interact with. Since the service could be written in a language other than Ruby, we could leverage the battle-tested librdkafka with which we were pretty experienced, since we used it from several Python and Go applications.
So we built Rafka - a proxy service that sits in front of Kafka and exposes it with simple semantics and a simple API. It provides sane defaults, hiding many details away from users. We chose Go, which already had a solid Kafka client library backed by librdkafka and also provided us with the necessary tools for efficiently implementing the features we needed.
We chose to use a subset of the simple Redis protocol, so that writing a client library becomes a straightforward task; all we had to do was add a thin layer on top of the well-proven Ruby redis client.
In a couple of days we had a working client library written in Ruby, packaged as a gem named rafka-rb, featuring both consumer and producer implementations.
With Rafka and its companion Ruby client library in place, our services and most importantly our Rails application could start writing and reading data from Kafka with minimum effort.
Our main Rails application is where most developers spend their time working on. Therefore, being able to easily write and deploy new consumers from within the application was of great importance. Therefore, the next step was to make it straightforward for developers working in the main Rails codebase to write and deploy Kafka consumers & producers in a consistent and straightforward manner.
Producing from a Rails application
Integrating producers in an existing application is a simple task, mostly due to the fact that only one producer is needed even if one needs to produce to multiple topics.
For this reason, we have a single producer instance that’s created during initialization and used everywhere throughout the codebase:
# config/initializers/kafka_producer.rb
Skroutz.kafka_producer = Rafka::Producer.new(...)Producing is as easy as:
Skroutz.kafka_producer.produce("greetings", "Hello there!")Consuming from a Rails application
Writing consumers is a whole other story, mainly since consuming is a long-running task. In this section we’ll take a look at how we provided the building blocks for writing consumers from within a monolithic Rails codebase, with the help of Rafka.
Links to the source code of all the outlined components are provided at the end of this post.
Let’s dive right in.
Consumers are plain old Ruby objects with their classes defined inside the
Rails application. They inherit from the abstract KafkaConsumer class, which
transparently integrates every consumer with statsd for statistics, Sentry
for error tracking and may provide other needed integrations in the future.
Their class names end with the “Consumer” suffix and the files that
define them are named accordingly, following Rails conventions.
A typical consumer looks as follows:
# kafka/price_drops_consumer.rb
#
# PriceDropConsumer consumes product change events, detects price drops and
# persists them to the database.
class PriceDropsConsumer < KafkaConsumer
# consumers call `.set_topic` to control the topic that's going
# to be consumed
set_topic "product_changes"
# a consumer must implement `#process`, which receives a message from the
# topic and does something with it
#
# @param msg [Rafka::Message]
def process(msg)
product_change = JSON.parse(msg.value)
PriceDrop.investigate!(product_change)
end
endWe should mention here that each consumer is backed by a
Rafka::Consumer instance
under the hood.
After writing a new consumer, it has to be enabled manually in the configuration file:
# config/kafka_consumers.yml
#
# This file defines which Kafka consumers run on production and how many
# instances are spawned on each server ('scale' setting).
#
# Each entry represents an enabled consumer and will result in that much
# consumer instances being spawned.
#
# The following enables `PriceDropsConsumer` and spawns 2 instances of this
# consumer on each server.
- name: "price_drops"
scale: 2Again, following Rails conventions, consumer names are derived from the class names.
A key point is that all instances of a consumer are essentially standalone Kafka consumers belonging in the same consumer group.
On deployment, Capistrano reads the configuration file to spawn the appropriate consumers on the appropriate servers (defined by a Capistrano role). More on that later.
Voila! This is all it takes to write and deploy a consumer.
Which brings us to the next question: how are consumers spawned as long-running processes?
Consumers as long-running processes
The natural step after having a bunch of consumers implemented was to actually run them.
This is achieved with a class named KafkaConsumerWorker which wraps
consumers objects and facilitates running them as long-running processes.
A simplified version of the worker is given below:
require "sd_notify"
class KafkaConsumerWorker
# @param consumer [KafkaConsumer]
def initialize(consumer)
@consumer = consumer
end
# Implements the consume-process loop.
def work
Signal.trap("TERM") { trigger_shutdown }
Signal.trap("INT") { trigger_shutdown }
SdNotify.ready
set_status("Spawned")
Rails.logger.tagged("kafka", "consumer", @consumer.to_s) do
Rails.logger.warn "Started consuming '#{@consumer.topic}'..."
begin
# main work loop
loop do
break if @shutdown
msg = @consumer.process_next
if msg.nil?
set_status("Working (consume timeout)...")
next
end
@offset = msg.offset
@partition = msg.partition
set_status("Working...")
end
ensure
@consumer.shutdown
end
end
end
def trigger_shutdown
@shutdown = true
SdNotify.stopping
set_status("Shutting down...")
end
def set_status(x)
SdNotify.status(
"#{@consumer} (offset=#{@offset},partition=#{@partition}) | " \
"#{Time.now.strftime('%H:%M:%S')} #{x}")
Process.setproctitle("consumer=#{@consumer} #{x}")
end
endThe worker ultimately ends up continuously calling the underlying consumer’s
#process method to process messages in a loop. It also provides graceful shutdown functionality.
Lastly, it integrates the consumer
with systemd, thus providing robustness, liveness checks, visibility and
monitoring capabilities.
Even though one won’t have to interact directly with the worker, it is quite easy to do so in case it is needed for development or debugging purposes:
consumer = PriceDropsConsumer.new(...)
worker = KafkaConsumerWorker.new(consumer)
# start work loop
worker.workThe next step was to start the worker using systemd. We did this with a straightforward systemd service file:
# /etc/systemd/system/kafka-consumer@.service
[Unit]
Description=Kafka consumer for MyApp (%I)
Wants=network-online.target rafka.service
After=rafka.service
[Service]
Type=notify
SyslogIdentifier=kafka-consumer@%i
ExecStart=/usr/bin/bundle exec rake kafka:consumer[%I]
WorkingDirectory=/var/sites/my_app/current
Restart=on-failure
RestartSec=5
TimeoutStopSec=30
NotifyAccess=main
WatchdogSec=600
MemoryAccounting=true
CPUAccounting=true
[Install]
WantedBy=multi-user.targetEach consumer instance is identified by a string containing the consumer name
and the instance number (e.g. price_drops:1), which is passed to systemd as a
template argument (the %i part). This way we can spawn many instances of
different consumers using the same service file.
Integrating consumers with systemd means that for each consumer we get several features out-of-the-box:
- consumer management commands (start, stop, restart, status)
- alerts when a consumer raises an exception
- visibility: what state each consumer is in (working, waiting for job, shutting down), its current offset/topic/partition (via sd_notify(3))
- automated restart of failed consumers
- automated restart of stuck consumers via systemd watchdog timers
- simplified logging: we just log to stdout/stderr and systemd takes care of the rest
Inspecting a consumer instance provides a pretty informational output which is useful for debugging when something goes wrong:
$ systemctl show kafka-consumer*
● kafka-consumer@price_drops:1.service - Kafka consumer for myapp (price_drops:1)
Loaded: loaded (/etc/systemd/system/kafka-consumer@.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2018-04-11 15:39:53 EEST; 24min ago
Main PID: 20543 (ruby2.3)
Status: "myapp-price_drops:server1-1 (offset=347720,partition=5) | 16:03:56 Working..."
Tasks: 2 (limit: 6144)
Memory: 310.4M
CPU: 17min 55.718s
CGroup: /system.slice/system-kafka\consumer\myapp.slice/kafka-consumer@price_drops:1.service
└─20543 consumer=myapp-price_drops:server1-1 Working...
Apr 11 16:03:53 server1 yogurt[20543]: [kafka] [consumer] [myapp-price_drops:server1-1] a log line
Apr 11 16:03:53 server1 yogurt[20543]: [kafka] [consumer] [myapp-price_drops:server1-1] another log line
# ...The last missing piece of the puzzle is the command that systemd calls in order to start a consumer. The command is actually a plain old rake task that sets up the worker along with its underlying consumer and runs it.
Similar to the other components, the task lives inside the Rails codebase:
# lib/tasks/kafka.rake
namespace :kafka do
desc "Spawn a consumer instance. The name and instance " \
"should be provided as an argument. For example " \
"rake kafka:consumer[price_drops:1]"
task :consumer, [:name_and_instance] => :environment do |t, args|
abort "Error: No argument provided" if args[:name_and_instance].blank?
parts = args[:name_and_instance].split(":")
if parts.size != 2
abort "Error: Malformed argument #{args[:name_and_instance]}"
end
name, instance = parts
consumer_group = "myapp-#{name}"
consumer_id = "#{`hostname`.strip}-#{name}-#{instance}"
consumer = "#{name}_consumer".classify.constantize.new(consumer_group, consumer_id)
KafkaConsumerWorker.new(consumer).work
end
endDeployment
Since we use Capistrano for deployment, we added a Capistrano task that takes care of stopping and starting consumers. A simplified version of it follows:
# config/deploy.rb
namespace :kafka do
desc "Restart kafka consumers"
task :restart_consumers do |t|
run "sudo kafkactl disable-and-stop"
consumers = YAML.load_file("config/kafka_consumers.yml")
consumers.each do |c|
run "sudo kafkactl spawn -c #{c['name']} -w #{c['scale']}"
end
end
endkafkactl is a wrapper script that executes the necessary systemctl commands under the hood.
When someone deploys the application, Capistrano reads the configuration YAML and spawns the enabled consumers as can be observed in its output:
$ bundle exec cap production deploy
# ...
** [out :: server1.skroutz.gr] Created symlink /etc/systemd/system/multi-user.target.wants/kafka-consumer@price_drops:1.service → /etc/systemd/system/kafka-consumer@.service.
** [out :: server1.skroutz.gr] Created symlink /etc/systemd/system/multi-user.target.wants/kafka-consumer@price_drops:2.service → /etc/systemd/system/kafka-consumer@.service.
** [out :: server2.skroutz.gr] Created symlink /etc/systemd/system/multi-user.target.wants/kafka-consumer@price_drops:1.service → /etc/systemd/system/kafka-consumer@.service.
** [out :: server2.skroutz.gr] Created symlink /etc/systemd/system/multi-user.target.wants/kafka-consumer@price_drops:2.service → /etc/systemd/system/kafka-consumer@.service.
# ...After deploying a new consumer we monitor the Grafana dashboards to verify everything works fine and we’re watching Slack to make sure no alerts are triggered.
The big picture
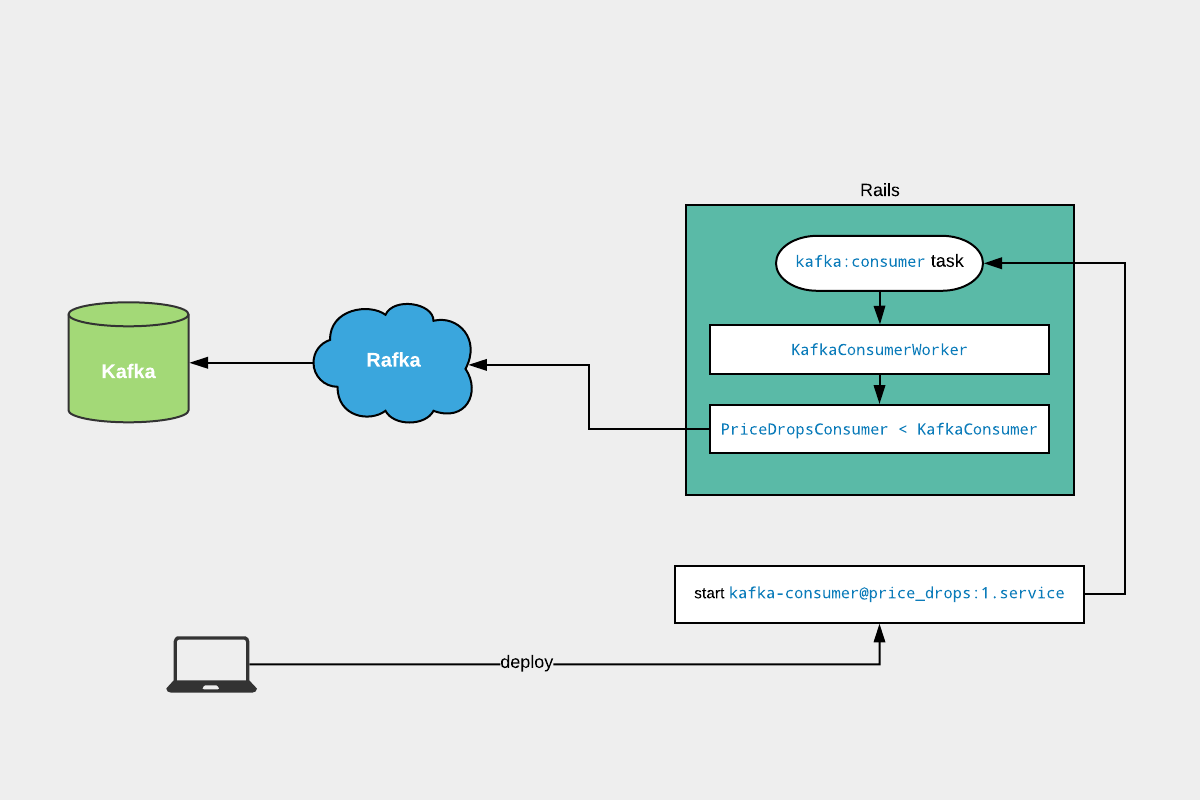
At a glance we can see that our Kafka/Rails integration infrastructure consists of the following components:
- Rafka: a Kafka proxy service with simple semantics and a small API
- rafka-rb: a Ruby client library for Rafka
KafkaConsumer: a Ruby abstract class meant to be sub-classed by concrete consumer implementationsKafkaConsumerWorker: a Ruby class that facilitates spawning consumers as long-running processeskafka:consumer: a rake task that runs a consumer instance- kafka_consumers.yml: a configuration file that controls which consumers should run on production and with how many instances
- kafka-consumer@.service: a systemd service file that spawns a consumer by calling the rake task
Their interactions are illustrated in the following diagram:
{kind=link}
We should note here that these concepts are orthogonal and each of them can be used separately from the others, whether it’s for debugging, testing or prototyping purposes.
Monitoring
Since many consumers would perform mission-critical tasks (e.g., calculate billing costs), it is imperative that they are sufficiently monitored.
Monitoring happens on various levels and each consumer transparently gets the following features:
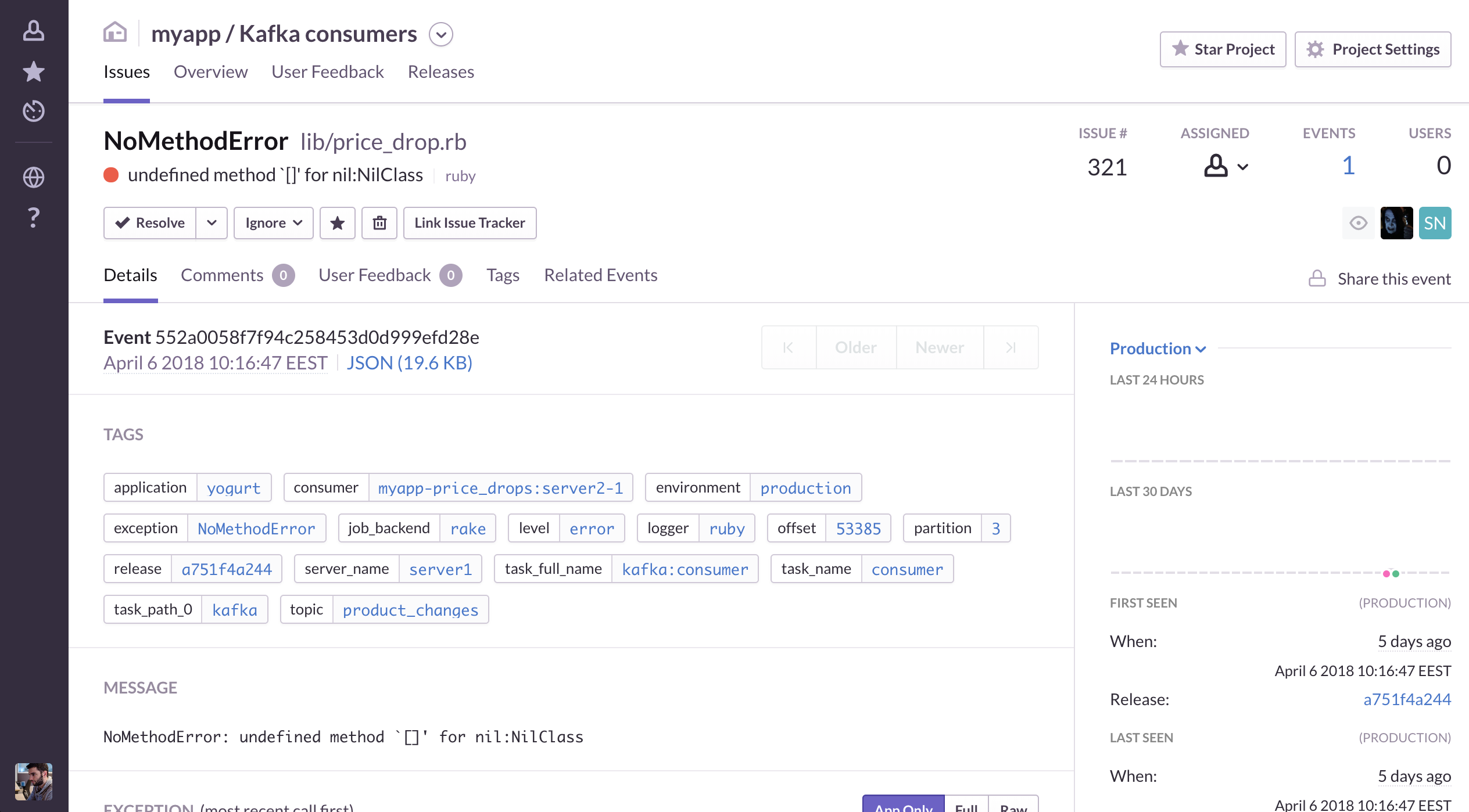
{kind=link}
- Statistics: job process timings and consumer throughput (processed msgs/sec)
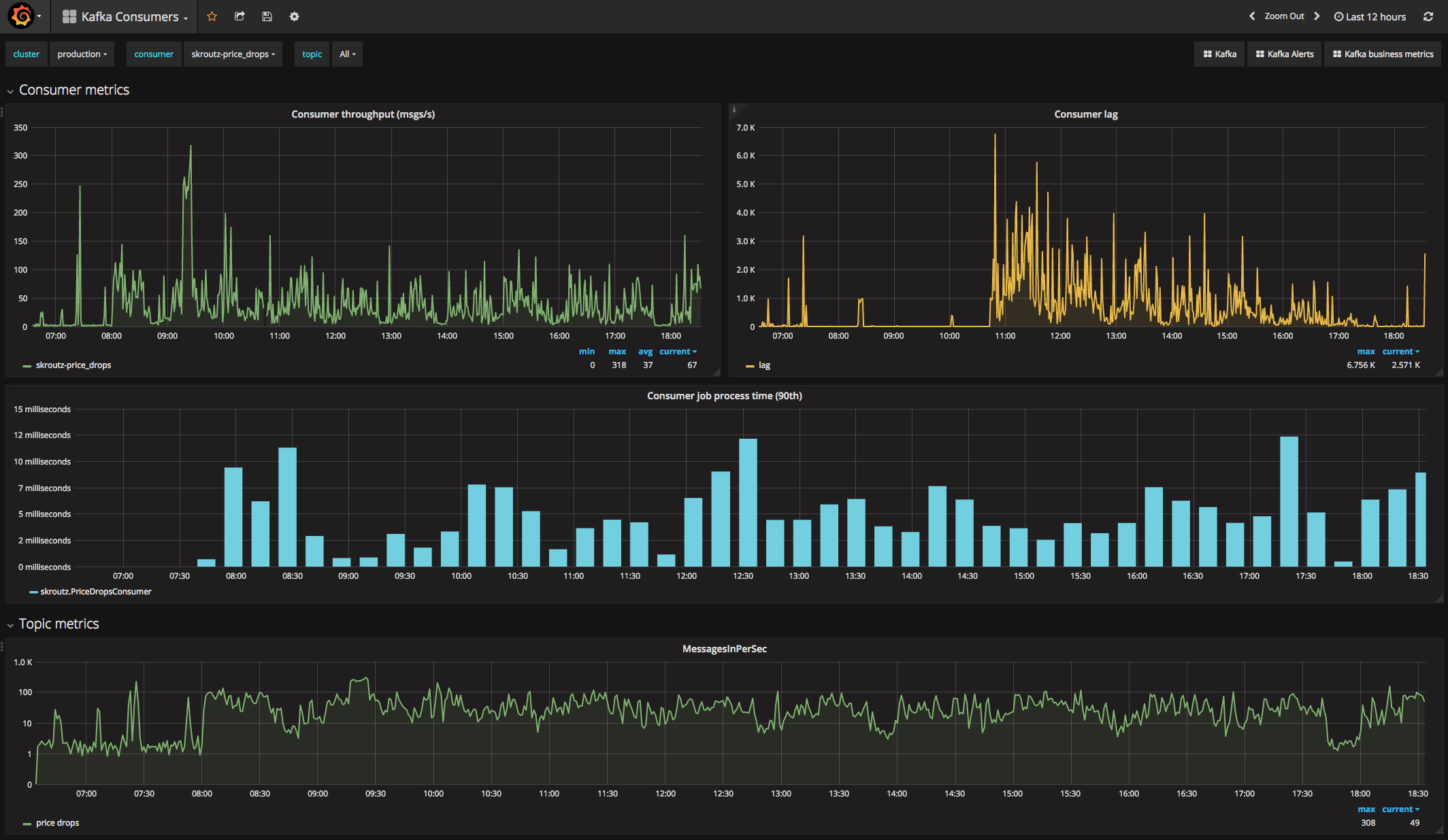
{kind=link}
The fact that we get these features out-of-the-box is one of the benefits of having a common consumer infrastructure.
Reflecting and moving forward
We are pretty happy with the way developers are interacting with Kafka and we received very positive feedback about it.
Being able to write and deploy consumers in a few simple steps increased the velocity of our development teams and enabled us to build on top of Kafka in a consistent and efficient manner.
In the future we want to package and distribute all the components described in this post as open source libraries (maybe a Rubygem) that other organizations can use and benefit from.
Finally, we plan to add more features to Rafka and the consumer/producer infrastructure, notably:
- batch processing capabilities
- multi-topic consumers
- KSQL-backed primitives (aggregations, joins, etc.)
- before/after/around consumer hooks
We would be happy to hear your thoughts and feedback!
Further resources
The code mentioned in this post can be found in the following repositories.
If anything is unclear or missing, please file a Github issue.