This is the story of how we improved one of our main services with minimum effort, by observing the available metrics and adapting to our needs the main job dispatching tool we use, Resque. That allowed us to scan shops in less time, using less resources and gave us the capacity to support more than double the current load.
Mo
Lets meet Mo, the service that keeps our product database up to date. It runs as a separate service from our main platform, Yogurt, and scans registered shops for product updates (additions, removals and updates). Mo downloads the feed (XML or CSV) provided by each shop, and finds any changes that took place since the previous scan. Next, it sends those changes to Yogurt so that they can be handled, persisted to database, or trigger relevant events etc.
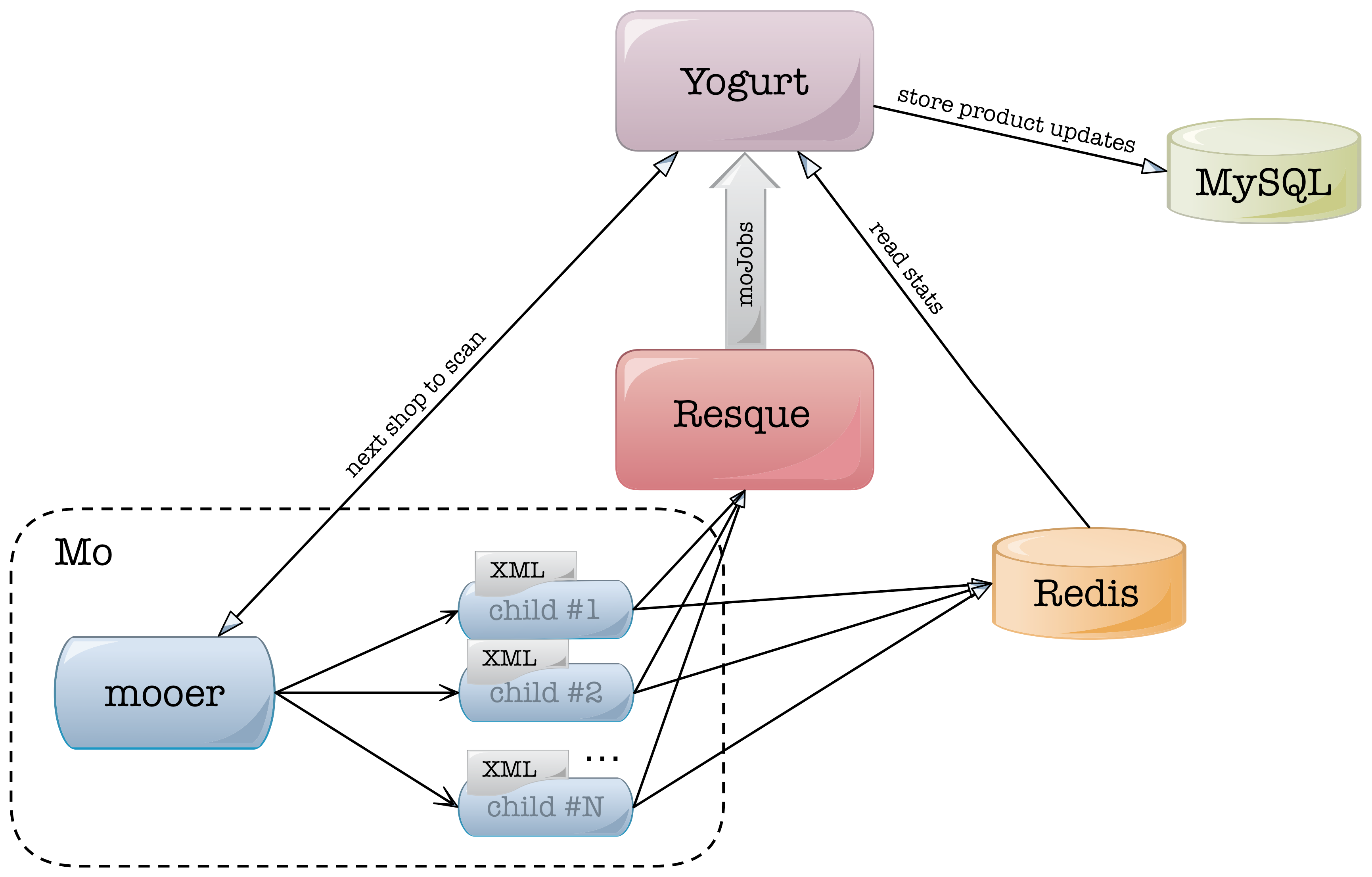
Mo scans every shop once during a given, fixed time interval, which we call the scan window. Scheduling is handled by Yogurt, and during a scan window, Mo repeatedly asks for new shops to scan until all shops have been scanned. For each shop, Mo forks a new process that does the actual scan. We put a limit on how many processes can work in parallel on every machine based on the available system resources.
During the scan, a Mo process does the following:
-
It downloads the shop’s feed
-
It parses the feed contents
-
It finds the differences between the stored products and the incoming ones
-
It sends any differences found back to Yogurt in order to process them
-
It updates the scan stats, like download time, process time etc
Once a process completes its job, it writes out the total stats to Redis, the common communication point with Yogurt, and exits. Its resources are released and a new process can be created to handle a new shop scan. All differences are converted to jobs and queued via Resque to be executed by Yogurt.
Resque
Resque is a Redis-backed background job processing system, initially developed by Github. It works using a throw-away process model where master workers listen on Redis for new jobs and then fork a child to execute each received job. For more info check out Github’s blogpost.
Slowdown and bottleneck analysis
Unfortunately, with all the years on its back, our faithful servant started showing its age: actual processing started outgrowing the scan window, which meant that we could not scan the affiliated shops for changes as fast as we would like. In extreme cases, scans for a small number of shops would be skipped completely and would be deferred to the next scan window. To be honest, we were probably giving Mo more that its old design could chew: processing more than 3000 shop feeds every hour is a different story than processing a couple of hundred feeds twice a day, as was the case when the system was first designed.
We started investigating the problem at hand, so that we could identify the bottlenecks that prevented us from keeping up with our growing needs to scan more shops, ever more often. As a first step, we dedicated some effort to enrich our monitoring and available metrics around our Mo stack; afterall one cannot improve what one can’t measure. By correlating all the metrics we had available, we knew that Mo worker processes were not the bottleneck: they were producing work faster than Resque workers could consume it. Since jobs queued in Resque seemed to take a lot of time to finish we were confident that something was fishy around there.
While looking around for any bottlenecks in our pipeline we stumbled upon this:
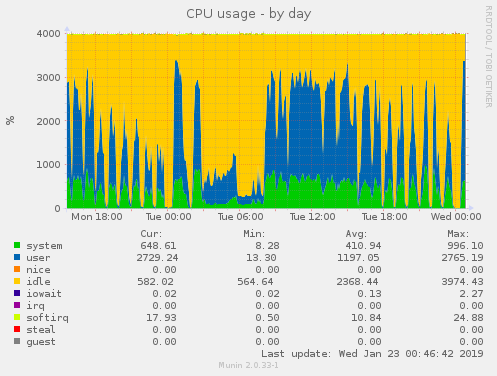
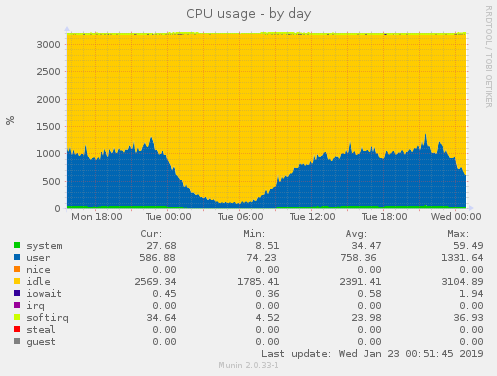
This is a snapshot of the CPU utilization of one of our Resque servers (left) and one of our application servers (right). During a typical day, they both handle comparable load, though it is evident that their use of the CPU differs heavily. We were burning a lot of CPU time doing things outside of our application’s load, as indicated by the system CPU time in green.
We also observed that Resque servers had a lot of network connection overhead (compared to their application server peers):
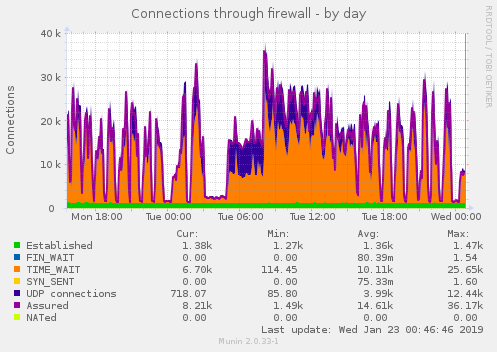
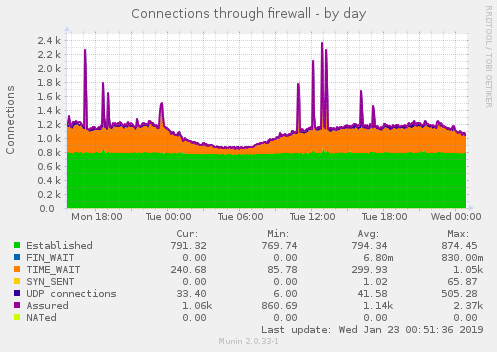
A lot of connections were left in TIME-WAIT state, a problem we already had to cope with in the past by using workarounds for TIME_WAIT port reuse net.ipv4.tcp_tw_reuse = 1.
With all of the above in mind, we decided to dissect the Resque jobs to see what was happening under the hood.
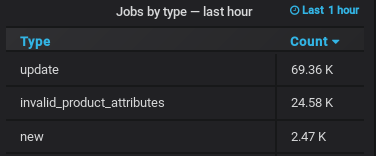
The vast majority of the jobs, created during a Mo scan, are product update jobs. These are in essence simple SQL update statements. A simple SQL update on our stack takes around 1 millisecond, but our measurements indicated that the Resque job wrapping the update took around a second to complete. Why were our jobs taking so long? We started to suspect that Resque jobs incurred some kind of overhead that clearly outweighed the actual processing. We threw stackprof to the rescue, which allowed us to obtain some flamegraphs and understand our job’s internal states.
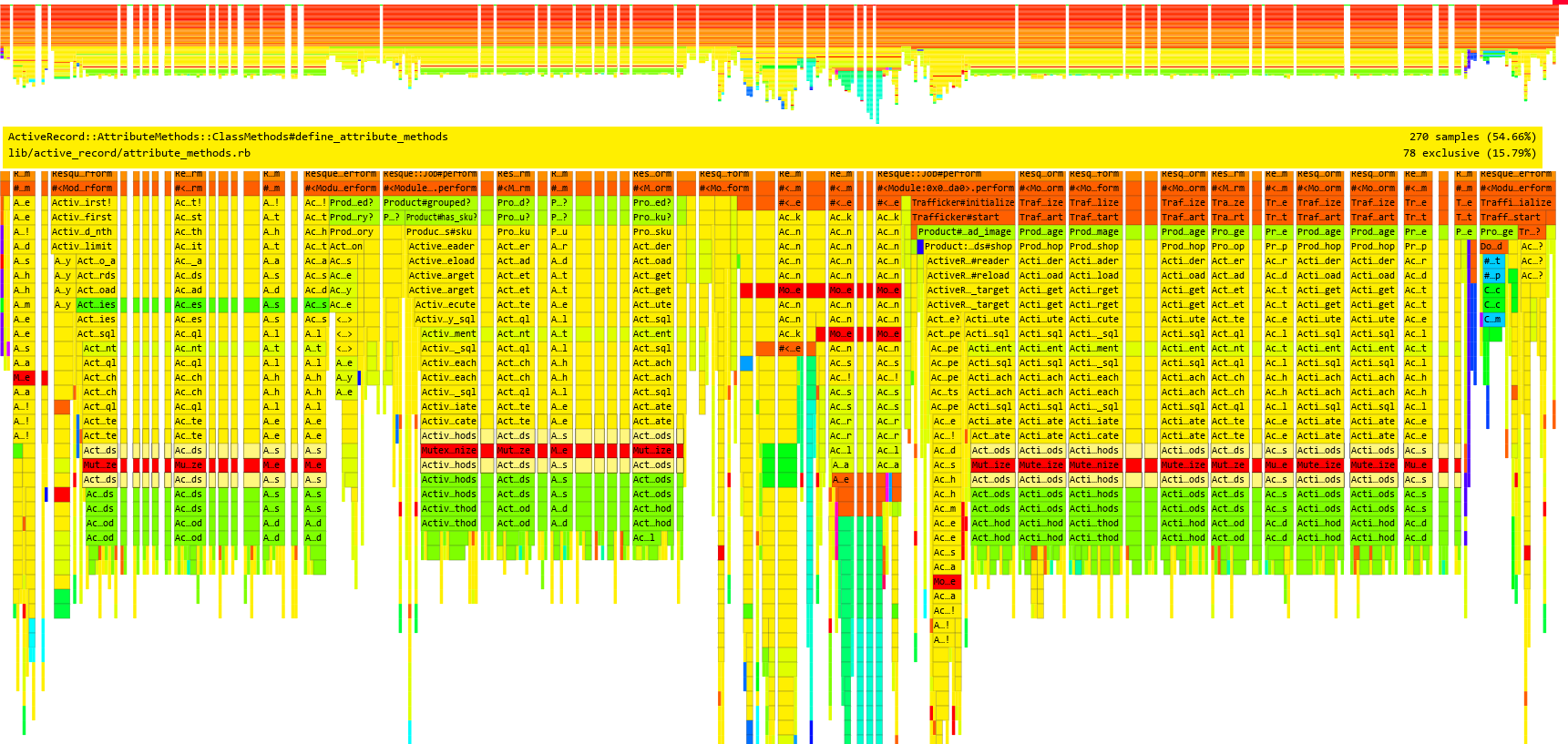
We were surprised to find out that more than 50% of the job’s wall time was squandered in define_attribute_methods. This is ActiveRecord’s way of picking up model fields from the database, instead of requiring them to be pre-declared. Model introspection happens the first time the model is used and this is happening everytime Resque forks a new worker.
ActiveRecord::Base.descendants.each do |klass|
begin
klass.define_attribute_methods
rescue StandardError => e
Rails.logger.warn("Failed to pre-warm #{klass}: #{e}")
end
endThe code snippet above shows how we implemented class method prewarming. We were aware that this didn’t preload any associations but even just model attributes would provide a lot of performance improvement.
Preloading ActiveRecord attribute methods before Resque’s first fork proved to be an effective step forward shedding ~200ms from our jobs with less than minimal code changes. The 20% gain in performance put a smile on our faces but we were aware that the actual overhead on our Resque jobs was around 70% so we definitely had to push ahead.
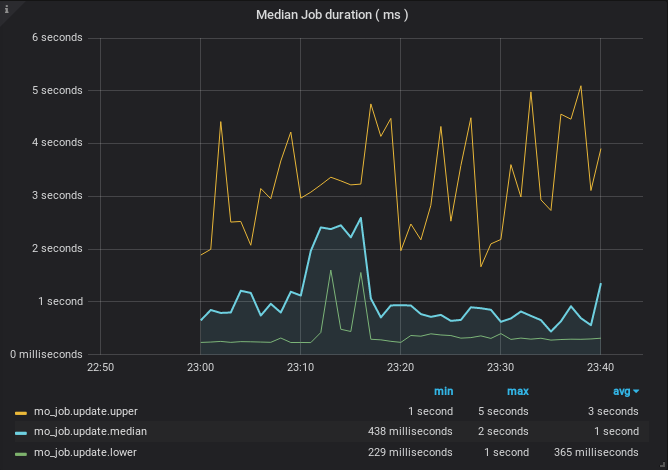

The results above definitely proved Rails is not a good match for short-lived tasks such as those created by Resque, and that made us pay a high tax on each job for using the Rails/Resque combo in these types of tasks. However, we didn’t want to ditch Resque completely, because it’s well-monitored and integrated with our deployment pipeline.
We were already aware that fork() puts a lot of pressure on the network stack because of database connection re-establishments (on top of model re-introspection mitigated above) so we decided to get a lot more out of our current setup and set off to explore the possibility of skipping forking altogether, while keeping our job code concise.
Non-forking to the Resque
Our next step was to evaluate how non-forking Resque workers could further affect the job execution time. Although it may sound like a silver bullet, forking can in some cases be useful, as it can isolate memory issues or prevent errors from propagating to the main process. Resque jobs are widely used for many other tasks inside the company like downloading images, moving a product to a specific category and more. As any task is of different value and urgency we have different queues, handling them accordingly. Taking all these into account, we didn’t want to apply non-forking behaviour to every case, so we decided to change only the one queue that handles Mo’s jobs to the non-forking version.
Resque had already implemented the option to disable forking in v1.23.1 and all we had to do was to upgrade our version of Resque, together with adding some extra configuration options in resque pool, the pool of resque workers.
We wanted to be able to define which queues will be non-forking, while keeping previous compatibility with the rest of the queues to be forking, so we extended the ResquePool configuration syntax. Upgrading Resque, also gave us some extra performance improvement “gifts”, like persistent Redis connections and job payload caching that led to fewer Redis queries.
The results we saw were impressive. In the following picture you can see cumulative job processing time, meaning how long these actions would last were they executed sequentially, and how it was affected after deploying our changes. It was moved from hours range to only a few minutes range, having the normal everyday load.
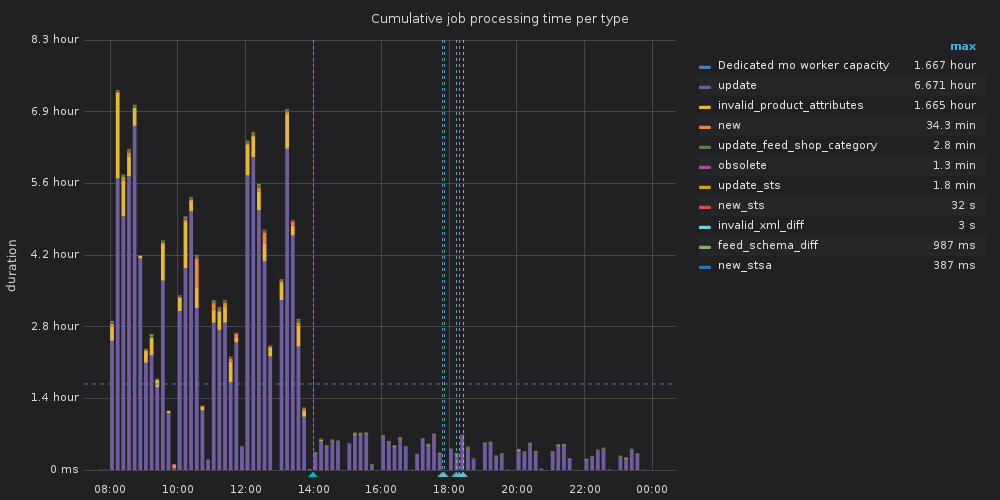
And this improvement was possible having less Resque workers running for Mo. Previously, there where 14 dedicated forking workers, plus some more from other queues that joined the group when they were idle; the current setup uses 10 dedicated non-forking workers.
Taking the new setup for a spin
One more thing we had observed was that many times workers had no work to do, as can be seen in the following graph:
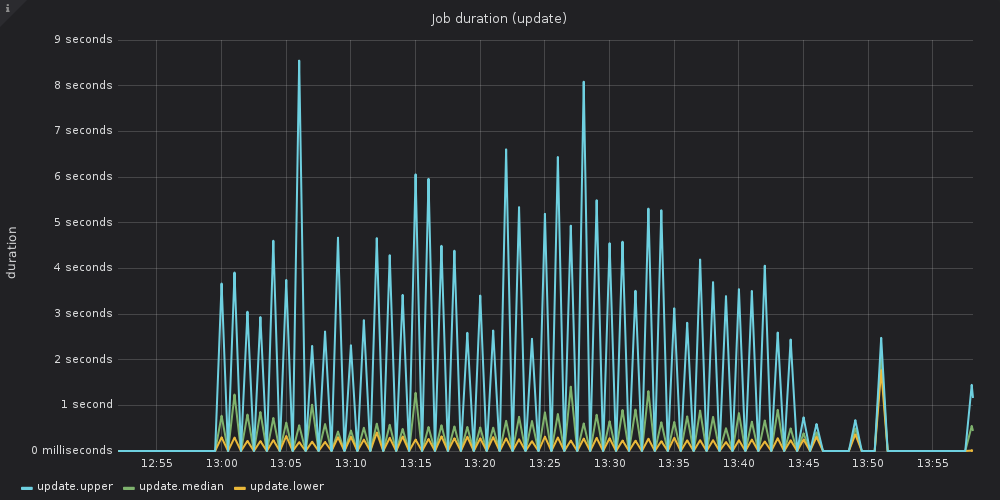
Local minima falling to zero indicate periods of complete worker inactivity. Naturally, our next step was to give Mo workers more load to work on and have less idle time, utilizing our resources as much as possible. We doubled the number of workers mooer could run in parallel and we saw scan window duration dropping instantly from 50 to just 20 minutes, scanning the same shop feeds and having less Resque workers!
Key takeaways
All these changes bought us some time for more improvements without redesigning our service internals, without investing on hardware or changing anything in our main codebase, Yogurt. We can now support at least double our current shops capacity without worrying that our resources won’t be able to handle them. At the same time, we also reduced pressure on other systems, such as the database servers. All it took was enhancing some missing metrics and observing how servers behaved under the given load, before attempting to redesign anything. These observations, along with a thorough investigation of how Resque works and its shortcomings, helped us in using it more efficiently, tailoring it to our needs, while keeping everything else intact.
Next Steps
Now that we have eliminated the primary bottleneck, we can focus on how to optimise our scanning workflow even further.
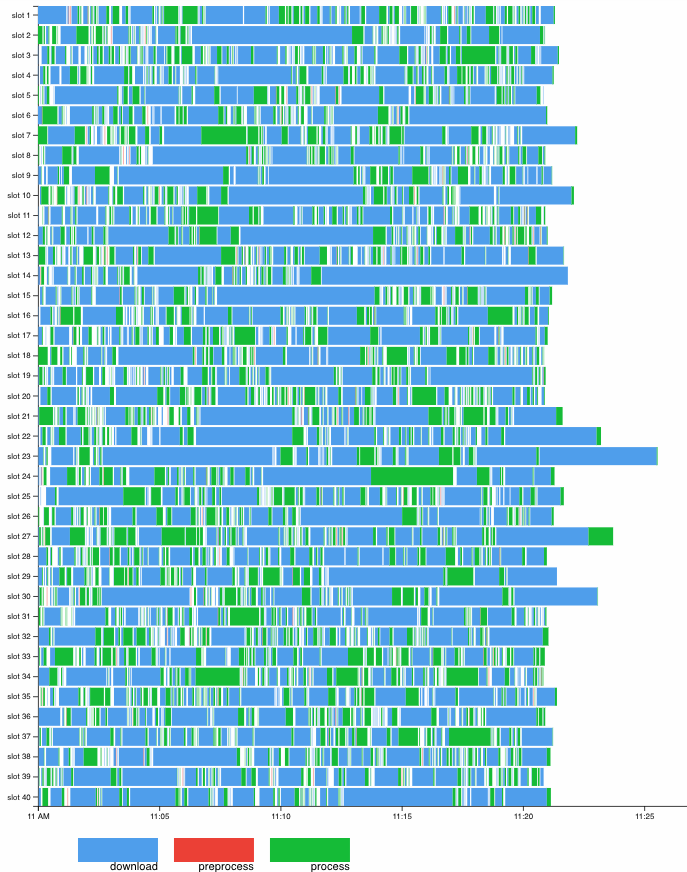
A first pretty low-hanging step will be to rethink our downloading process, since it is the most time-consuming operation (depicted in the graph above). Mo workers currently do a mix of I/O and CPU-intensive work (downloading vs processing), while being limited in parallelism only with the CPU-intensive work in mind. This leads to suboptimal resource usage, that can be improved by boosting the download parallelism. Putting our external downloader service to use could offload downloads from Mo and let its workers do even more of what they are good at, feed processing. In the more distant future, we will investigate moving from rigid scan windows to a more suitable scanning solution with well-defined SLAs, which will give us more flexibility in our workflows and rid us of some of the burden caused by the bursty nature of scan windows.
Authors: Olia Kremmyda & Dimitris Bachtis on behalf of the SRE team