Maintaining a high velocity in development teams requires us to continuously improve our daily workflows. Build pipelines specifically, make up for a big chunk of these workflows since they’re involved whether we’re developing, testing or deploying our code.
At Skroutz it’s not unusual to perform over 30 deployments during the course of a day, while the test suite needs to be run even more frequently. And that’s for the main application only.
As our organization grew, certain build pipelines got slow to the point where they became too disruptive. After all, each minute we’re waiting for a deployment to finish means we can’t work on things that matter.
In this post we will see how these issues led us to create mistry, an open source general-purpose build server.
Background
Our infrastructure is hosted and maintained in-house, so it was a straightforward process to determine where the majority of time was spent during our most critical pipelines.
With proper instrumentation set up, we could start pinpointing significantly slow processes in our daily workflows.
Asset compilation
Asset Pipeline is the Ruby on Rails component that takes care of minifying, concatenating, obfuscating and compressing web assets (mostly JS and CSS files); a process called asset compilation. The compiled asset files are those served to the end users. This can be a slow process depending on the size of the application.
In most conventional Rails setups, asset compilation happens as part of the deployment process. To deploy the main application, we use Capistrano:
$ cap production deployCapistrano then takes over and sequentially executes a bunch of commands (copy the new code to application servers, restart services etc.) One of the commands is the following:
$ rails assets:precompileThis compiles the asset files and saves them to a specific path in the local file system. Eventually the files are copied to the application servers ready to be served to the end users.
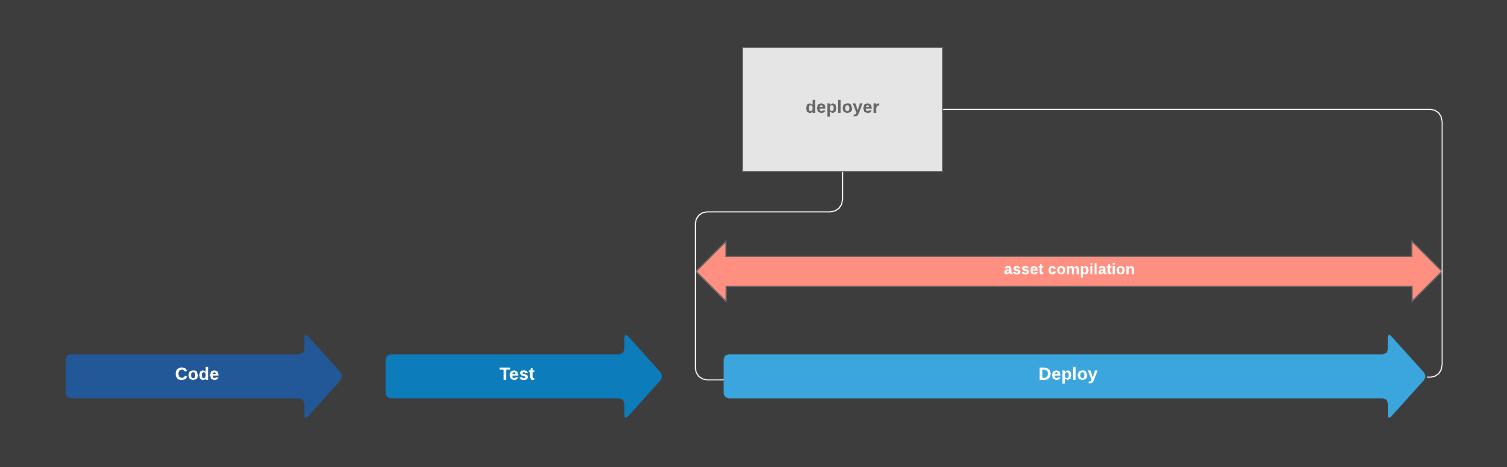
In our setup, deployment commands (including asset compilation) are executed by a dedicated machine, unsurprisingly called the Deployer. At a high level, the process is illustrated in the following diagram.
{kind=link}
Deployer is a black box for most development teams, which means there is no visibility in the asset compilation process. For example, one cannot easily inspect the assets for development or debugging purposes.
Most important is the fact that asset compilation is tightly coupled to the deployment process. This has important ramifications, one of them being the fact that when a revision is deployed to staging and then to production, assets have to be compiled separately each time for both environments, even though the resulting files are identical.
Dependency resolution
Another process significantly slowing down our workflows was dependency resolution.
In order for the main application to boot, its runtime dependencies must be present in the system. This means that CI workers, application servers and engineers must all go through dependency resolution multiple times a day.
Dependencies are essentially Ruby libraries (a.k.a. gems) that are managed by Bundler. Given some files that describe the set of application dependencies along with their version constraints, Bundler decides which gems are needed and downloads them.
A typical Rails monolith contains hundreds of dependencies, which makes dependency resolution a slow process since it involves a lot of network I/O.
The premise
By reflecting on the aforementioned processes, we spotted an opportunity of saving significant amounts of time and resources in a non-disruptive manner; that is, without major changes to our infrastructure or workflows.
We noticed a common pattern among these pipelines: a command is executed with a certain input, we wait until it’s finished and then use its output. The key observation however, is that the output is purely dependent on the input.
- in asset compilation the input is the application source code (everyone can compile the assets provided the code), while the output is the actual assets (CSS, JS files).
- in dependency resolution the input are the files that describe the dependencies of the application and their versions, Gemfile and Gemfile.lock; while the output is the resulting gem bundle (i.e. Ruby source files).
Given the above observations, we had some ideas in mind.
Since we know the command will be executed sooner or later (e.g. assets will have to be compiled when we eventually deploy), we can execute it now and save its output for whenever it’s needed. So by the time it’s actually needed, the output will be readily available, saving a lot of time in the otherwise slow process.
For example, we can compile the assets right after a commit is pushed to the master branch. This way deployment will not stall waiting for the asset compilation; the assets will be ready and will be shipped right away to the application servers.
Furthermore, the fact that the output is purely dependent on the input means we can save outputs of individual command executions and reuse them when identical commands (i.e. same input) are to be executed.
For example, given a Gemfile and Gemfile.lock, we can perform the dependency resolution once, save the resulting bundle and reuse it between multiple machines that would otherwise have to go through the same resolution process again.
Both of these optimizations could save us a lot of time and computational resources.
The solution
To bring the above ideas to life, we imagined some kind of build server able to execute arbitrary commands inside isolated environments (we’ll call these executions “builds”).
Builds produce a desired output (we’ll call them “artifacts”) that is saved in the server and is readily available to anyone that needs it.
Builds can be scheduled by humans and machines alike and the resulting artifacts can be downloaded from the server. Progress of builds can be inspected via a web interface exposed by the server.
Together with the server we imagined an accompanying CLI client, offering a drop-in replacement for the currently slow commands in our existing pipelines. So instead of executing the actual command, we would execute the CLI that schedules a build in the server, waits until it’s complete and then downloads the resulting artifacts.
The end result would be the same as before: some files (the artifacts) are saved
in the system that executes the command. In the case of web assets,
the asset files are placed under public/assets. In the case of Bundler, the
gem files are placed under vendor/bundle.
This way changes in our workflows are kept to a minimum. For example, in the deployment process only a single line would have to change, from:
# compiles assets and saves them to public/assets/
$ rails assets:precompileto:
# schedules a build to compile the assets, waits until it's finished and
# downloads the resulting artifacts to public/assets/
$ imaginary-cli build rails-assets --path public/assets/After this seemingly small change however, the pipeline would be much more efficient:
- work is performed at most once since results are reused between identical command invocations.
- work is performed eagerly so that results are readily available by the time they’re needed.
These optimizations minimize resource consumption in terms of CPU, memory and network bandwidth, but more important, they make the develop-test-ship cycle faster by reducing the execution time of our core pipelines.
Implementation
After some brainstorming sessions we had the main idea sketched out. We moved forward with a prototype implementation after setting the initial requirements:
- custom build recipes and execution environments should be supported (we call these “projects”). Anyone should be able to add their own project.
- builds should run in isolation from one another and in a sandboxed environment.
- builds should be parameterized. For example, we should be able to compile the assets of our Rails application for a specific revision (i.e. SHA1 of a commit).
- builds should be optionally incremental (a.k.a. partial builds). The Rails Asset Pipeline for example, caches intermediate files when compiling assets so that subsequent compilations are faster. Similarly, Bundler skips gems that are already present in the file system. To support such cases, the server should optionally persist selected files across builds of the same project.
Containers were a natural fit for the first two requirements. We decided that build recipes would be provided in the form of Dockerfiles. This makes builds essentially Docker images that are executed to produce the desired artifacts. Containers provide us with the isolation we want, while engineers can run the builds in their own machines for debugging purposes, using the very same images the server uses.
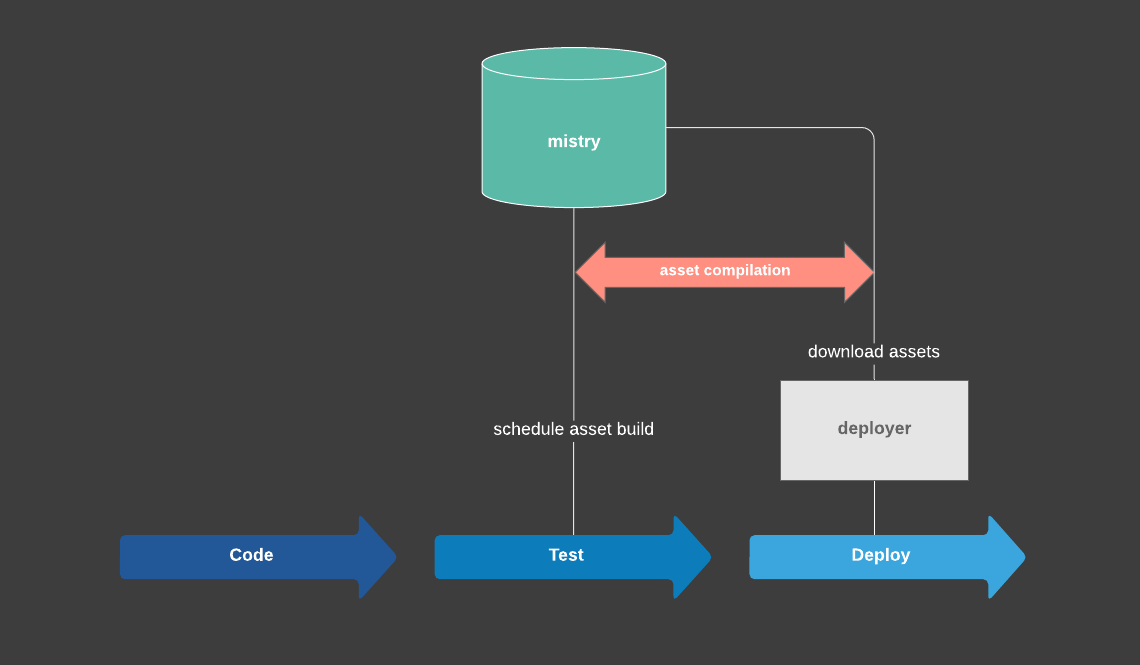
We decided that the server would expose a JSON API for clients to interact with. Together with the server (mistryd), a client CLI (mistry) would be used to schedule builds by interacting with the JSON API. When scheduling a build, one has to specify the project (recipe) and optionally some build parameters. After it’s scheduled, the CLI blocks until the build is finished and finally downloads the resulting artifacts using rsync.
# schedule a build with a custom parameter (commit) using the CLI client and
# download the artifacts when finished
$ mistry build --host mistry.skroutz.gr --project rails-assets --commit=ab34afWe chose the rsync protocol for transferring build artifacts. This means network usage is minimized since files are only downloaded if they are not present (or if they have changed) in the local file system. This is important since we knew the majority of web assets remain mostly unchanged between application revisions. The same is true about dependencies, they don’t change very often between different commits.
Choosing a file system
We knew artifacts could potentially occupy a lot of disk space, since for instance, assets would have to be saved in the server for each revision of the application. As another example, in case of dependency resolution a gem bundle can easily result in hundreds of megabytes. Keeping different gem bundles in the server would quickly result in excessive disk space consumption. Fortunately there was a way to tackle this issue.
The key observation here is that many of these artifacts are identical between builds. For example, as we mentioned above only some assets usually change (if at all) between revisions of the application. Also most of the dependencies are not changed between revisions, which means a large portion of the gem bundles remains unchanged.
Copy-on-write (CoW) file systems to the rescue. For minimizing disk usage in such usage patterns and also to support incremental builds, a file system with copy-on-write semantics was a natural fit. In a CoW file system, even if multiple copies of the same file exist (or large files with very few differences between them), the data blocks are not actually duplicated. In our case where most of the application assets and dependencies remain unchanged, this translates to significant disk space savings.
In CoW file systems, cloning files or entire directories is naturally a fast operation, since data blocks are not actually copied in the traditional sense (i.e. they’re not duplicated). This fits great for supporting incremental builds, since we can copy almost instantly the artifacts of a previous build to serve as a starting point for a new build.
We went with Btrfs with which we were already familiar, as our production file system. However we designed mistry to support pluggable file system adapters. In that sense, adding support for another file system like ZFS is fairly straightforward.
The result
After a few iterations we had a working build server that served all of our aforementioned needs.
By incorporating mistry in our build pipelines, deployment times were reduced by up to 11 minutes (that’s how much compiling the assets previously took). The migration was transparent and didn’t disrupt any workflows of the engineering teams. Nothing has changed on the surface, yet things have changed under the hood. During deployment for example, Deployer does not actually compile the assets anymore but merely fetches them from mistry.
{kind=link}
We call mistry a general-purpose build server because it can be used to
speed up different kinds of pipelines. Asset compilation and Bundler dependency
resolution happened to be the cases that affected us the most, but there are
many other potential use cases. For instance, we plan on using it to speed up
yarn install invocations and we recently started using it for generating our
static documentation pages.
mistry is open sourced under the GPLv3 license. There are still a lot of rough edges (e.g. the web view is a bare-bones page without much functionality outside of showing logs) but the core is fully functional. It can be deployed with different kinds of file systems, although Btrfs is recommended for production environments.
As a next step, we are planning to open source our build recipes for everyone to use.
Documentation can be found in the README and in the wiki. Please let us know if something is missing.
Conclusion
This was the story of how we spotted the opportunity for improvements in our daily workflows and built a tool to implement them.
We’ve been using mistry in production for a year and we are pretty happy with it. There are a lot of features and enhancements to be done yet; contributions are more than welcome.
We encourage you to give mistry a try if you believe it might be a good fit for your projects. Feel free to open an issue for bugs, questions or ideas.
We’d be happy to hear any feedback in the comments section.