Powering Search
At Skroutz we make extensive use of Elasticsearch. One of the major use cases is powering the site’s search and filtering capabilities that assist our users finding the product they are looking for. We are happy to serve around 1.2M searches on an average day.
At the heart of search, lies Elasticsearch and its documents. Each document corresponds to a categorized, manufactured item available for sale, namely Stock Keeping Unit, or SKU for short. Searches require complex queries that involve multiple attributes composed by several of its database record values along with several fields calculated during serialization. Some of those attributes are:
- SKU name
- Category name
- Manufacturer name
- Minimum price
- Current Availability
Numerous changes, such as product price updates, are performed on our relational database almost constantly. Modifications should be reflected to the Elasticsearch index state with as little latency as possible, thus keeping the search results up to date. The nature and origin of the changes varies, as we collect the availability and price information from shops that we collaborate with at regular intervals. In addition, our Content Teams continuously enrich SKU, manufacturer or category information, which also may happen through automated, complex pipelines, such as category classification operations.
It becomes apparent that we need a robust way to keep the database and the Elasticsearch documents in sync. Our choice is asynchronous updates triggered by hooking into ActiveRecord, as we are powered by Ruby on Rails. We are writing to the database synchronously since we consider it our ground truth. However doing the same in Elasticsearch for every single event would add a major performance overhead on each transaction, as the serialization process is inherently expensive. Asynchronous updates allow for retries in case of possible intermittent failures. The indexing operations are designed to be idempotent and resilient to certain failure scenarios, so the sequence of updates for a single document can be repeated or reordered, thus the index state will eventually converge.
The Beanstalk era
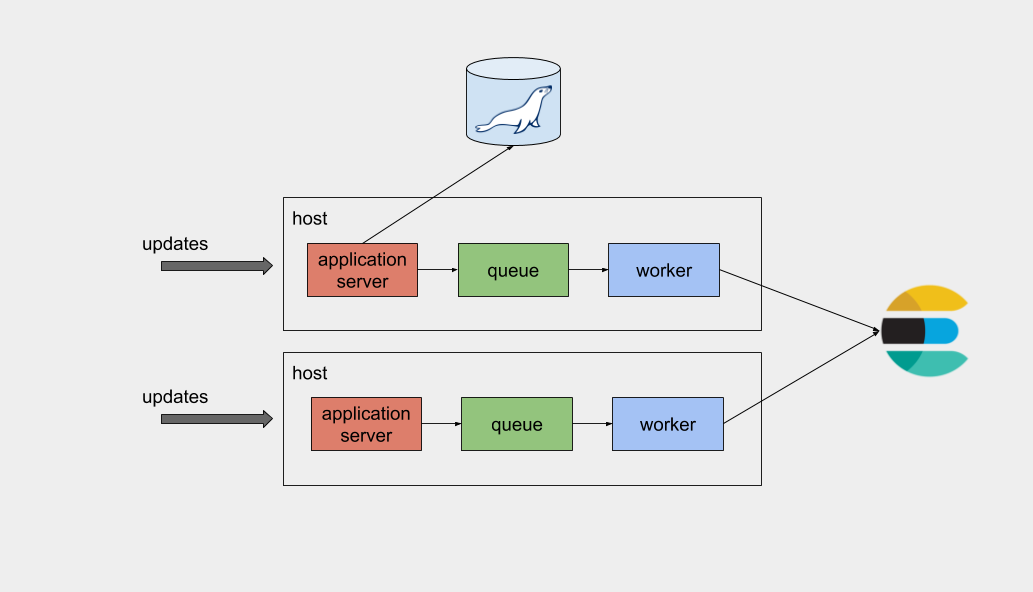
Our legacy implementation used a popular tool called
beanstalk; a work
queue daemon with a simple architecture. It accepts messages through the
network and holds everything in memory, while also employing a write-ahead log
for persistence. A beanstalkd process was co-located with every application
server of our fleet and every time an update occurred in the database, the
application enqueued a message to beanstalk. The worker process would then
consume the message and perform the necessary work.
{kind=link}
This pipeline has a few problems. This beanstalk ensemble is not centralized, which translates to an uneven load distribution among workers. That decentralized aspect also complicated our deployment process, as we had to account for many hosts in case we wanted to retry or debug something. Consider what happens if a change affects multiple documents. An update on an associated entity (such as a category name change) would mean that we need to update any affected fields for all SKUs associated with said entity. As with individual updates, this associated entity update will be handled from an application server so it would block the entire queue, while all the others workers are idle. As mentioned before, we have to use denormalization in several cases in order to make the SKU attributes searchable.
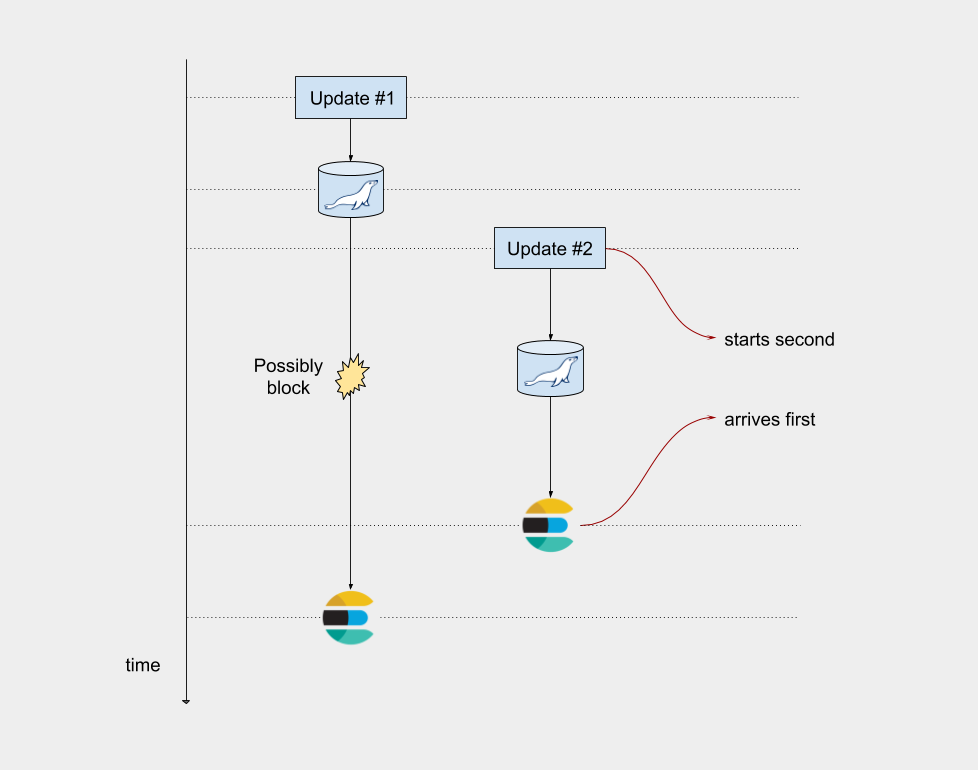
Another big concern of ours, was that updates for a single entity were not ordered. An example will clarify the situation. Let’s imagine two update events for the same SKU occurring simultaneously or very close to each other. It’s a matter of chance which application server will handle each request, and it is almost certain that they will end up at different servers, and thus different beanstalk queues. If the processing times overlap, a race condition could occur. This is highly unlikely to happen but we wanted to remove this possibility entirely, since it adds some mental overhead, particularly as the application scales.
Here is a diagram illustrating the race condition
{kind=link}
This solution served us very well for many years, but due to our scaling and operational needs, we decided it was time to move on to more sophisticated pipelines.
Considerations for the new Message Queue
Given that we usually have to process hundreds of thousands of updates daily, it was necessary to be able to decouple them from the primary database updates and also be able to keep track, monitor, and possibly automatically retry them in case of an intermittent failure. Another concern of operational nature, is the ability to be able to perform a point-in-time recovery process, which can happen in case of a bug or if an index modification requires re-indexing. In this case, we need to identify which documents were modified during a given time range, and be able to perform the necessary update operations again, so that the Elasticsearch state eventually converges.
As discussed, we had some problems on our hands:
- Eliminate race conditions (strict ordering)
- Introduce distributed processing (horizontal scaling)
- Introduce persistence
- Introduce pause and rewind capabilities
Regarding the concurrency issues, we could take advantage of Elasticsearch versioning. Provided that we would always send the current version of the document along with the update request, this technique would render our potential race condition issues impossible. However, that would increase the contention on the Elasticsearch cluster and our database because that would also require help from it as the Elasticsearch document version would be stored there.
After some whiteboard sketches, we decided to go with Apache Kafka, as the use case sounds well suited for it. We already are huge fans of the system and we have a production cluster deployed for other company projects, so this was a no-brainer.
The new pipeline
Kafka is a distributed log at its core, offering by default both distributed processing and strict ordering guarantees. Both of these aspects are a result of an ingenious and pretty simple decision. In Kafka, a stream of records is called a topic. A topic is split into partitions, and the cluster allows only a single consumer to read from a partition. To accomplish strict ordering and avoid race conditions, we also need all messages that concern the same entity to be consistently stored at the same partition. Since the client determines the partition of the topic that a message will be stored in, this can be accomplished by using the document ID (database primary key) as a key. Partitioning schemes may vary, with the simplest being hashing the key value and applying a modulo operation, with the divisor being the total number of partitions.
Furthermore, Kafka also offers substantial throughput, by distributing partitions evenly across many machines (called brokers). All published messages are persisted on disk, so there is no possibility of message loss. Messages are not removed after being consumed and Kafka stores the per-partition offset that each consumer group has reached. Retention period is customizable and messages are available for several days after their consumption.
This explanation could go on forever if we were to get into more intricate details about Kafka, so we’ll refer you to the official documentation.
Our architecture can now distribute the load to multiple consumers while also having persistent and centralized storage. It looks like this:
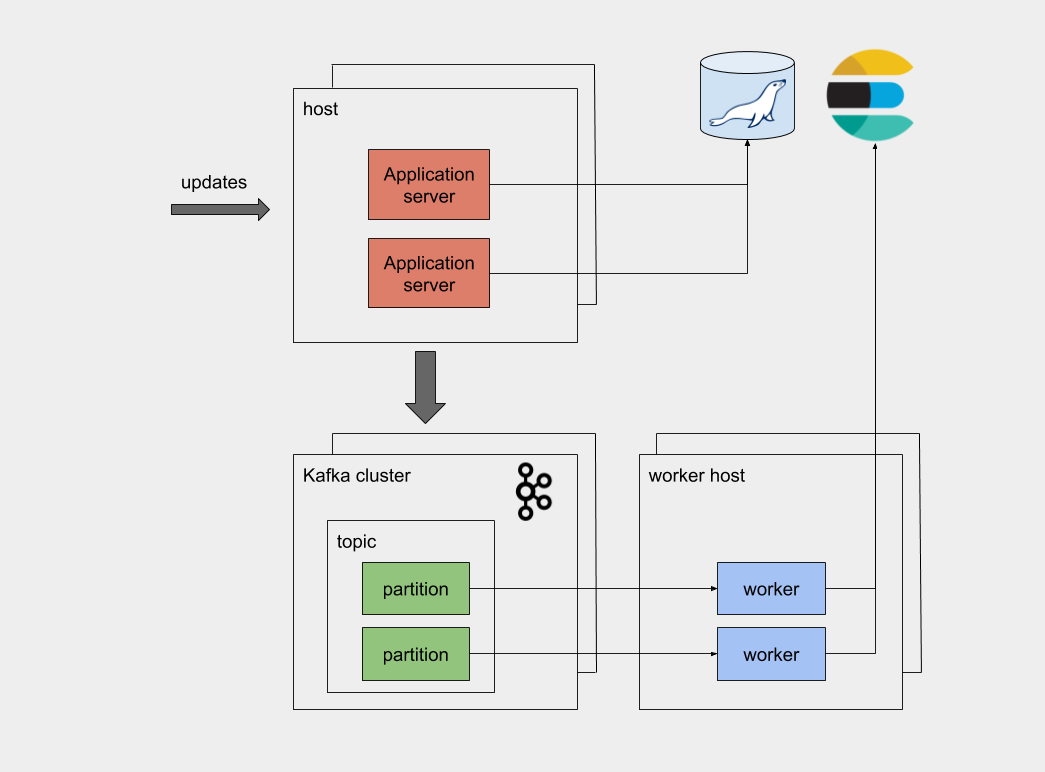
{kind=link}
This offers us a much more future-proof architecture that can withstand growth. It gives us the ability to quickly add more resources to a bottlenecked component. In case our load increases in the future, topics can easily be repartitioned to allow for more consumers in a matter of minutes, thus allowing us to add more workers to the pool. Kafka guarantees that after the rebalance, the order is still strict and the updates are distributed and blazingly fast.
The use of Kafka also allows us to have more visibility and finer operational control on the whole pipeline process. In the old architecture, all workers had to be stopped for the process to be paused. However, in Kafka, the position of each consumer (which is called offset) is maintained by the cluster and can be rewound based either on a timestamp or on an explicit offset position. Therefore, we are now one command away from rewinding the consumers to the position they were, say, two hours ago. This is a tremendous gain, in cases of bugs or maintenance windows.
Achieving strict ordering
One of the biggest problems that we faced while implementing the aforementioned solution was bulk updates. As described, there are some kinds of updates that concern multiple documents, such as a category update. On our legacy pipeline, these updates were handled by the Elasticsearch Bulk API mainly for performance reasons.
However, since we wanted to preserve strict ordering, we needed to do some kind
of unrolling of those bulk updates into their respective document level
updates and enqueue those documents consistently using the same topic and
message key. We’ll take the category update as an example again. If the
category has N SKUs, we need a service to produce N messages,
one update message for each SKU.
Besides correctness, another reason to implement the unrolling process was to
ensure that processing time on the consumer remains low. Kafka is generally
optimized for small message processing times and consumers are required to
continuously verify that they are working, as a liveness check. Failing to
send heartbeats causes a session timeout. It is configurable by the
session.timeout.ms variable, but a high value is not recommended.
If a consumer is executing a long-running process, the broker can potentially consider the consumer inactive and will trigger a rebalance, thus removing it from the consumer group. That same message, however, will be picked again by another consumer, after the rebalance, since the cluster thinks that the message has not been consumed yet. One can understand that if the job is inherently big, this can go on forever, triggering rebalances and timeouts every time and effectively bringing the whole pipeline to a halt.
Implementing the above correctly was tricky because the unrolling process itself can end up going over the Kafka processing limits. We ended up with a “two-level unrolling” technique. Processing a bulk update message will first split the entire document collection to batches of a predefined size (e.g. 1000) and produce one message for each batch. When each batch message is in turn consumed, it produces the corresponding update messages in the document-level update topic.
For code simplicity, developer sanity, and correctness, we considered having a dedicated topic for each different type of update, but we settled with two. The first topic and its consumers handle the bulk updates and enqueue into the second topic which actually performs the Elasticsearch write requests. Of course, most flows in our application enqueue directly into the document-level update topic.
Adaptive Throttling
Early on during development, we encountered a problem. Now that the bulk updates that come through are translated to document level updates, our system could easily flood itself, because producing a message to Kafka is of the order of a millisecond per message and during unrolling we can potentially produce hundreds of thousands of messages.
Therefore, bulk updates are expected to be completed, at a later time (depending on the number of affected SKUs). On the other hand, individual updates should perform with low latency, as the changes are generally expected to be visible in search results within seconds.
Kafka does not support priorities at all, and we could not implement a priority system on top of it, because we would lose the strict ordering guarantee. We needed a mechanism which would monitor and throttle the bulk consumer processes specifically when there were more urgent updates that need to pass through.
We ended up using an external counter in order to coordinate that process. The concept was that we would allow only a certain number of updates that originate from a bulk update operation to be enqueued within a certain time interval.
The flow is as follows:
- A new bulk update is generated and is consumed.
- It is unrolled into smaller batches, each one covering a different range of the SKU primary-key space.
- Batch messages are again consumed by the same consumer. If the counter is zero, the consumer will increment it by the size of the batch. Otherwise, it switches to a polling mode until it becomes zero, thus throttling the process.
- The consumer will then proceed to enqueue the document level messages.
- The Document-level consumers will pick them up, and upon completion the counter will be decremented by one.
Eventually the counter will reach zero, when the batch is done, effectively
allowing the next batch to be enqueued. This enables time windows for other
updates to be enqueued and processed. Note that we also check whether we are
about to cross the Kafka session.timeout limit at step (2) above, since the
total processing time should not exceed this threshold. So there are two
termination conditions for the polling loop.
The concept is that a feedback loop is established between the two consumers, allowing the batch consumer to have an insight on whether the document consumer has the availability to process the next batch. Additionally, in cases where we need to throttle more aggressively, we can reduce the batch size and the system will adapt.
Redis was a strong candidate for such a counter since it is accessible from all the consumers and can be easily monitored and operated upon in case we needed to run ad-hoc commands for debugging reasons. Its atomic operations and TTL capabilities were also important properties, as we also have a TTL on the counter in case something goes wrong and becomes stale.
Conclusion
We are pretty satisfied with this new pipeline, and we enjoyed the ride, learning a lot about Kafka and distributed systems in general. Apart from much greater performance, we feel our new architecture will last for many years to come, as it offers huge flexibility to both our developer and operations teams.
If you have any questions, ideas, thoughts or considerations, feel free to leave a comment below.