Skroutz is the leading prices and products comparison engine in Greece, a major player in Turkey and a rookie in the United Kingdom. It currently indexes about 7.5 million products from 1500 shops. About 4 million unique users use it on a monthly basis to find the best offer for a product based on several criteria like price, availability, products reviews and many more.
How we gather data for the index
Every shop indexed by Skroutz must provide a url for an xml feed, which is essentially a catalog of its products. The content of this feed is straightforward: it includes all the products of the shop alongside properties like price, availability etc. An example for a single product might be:
<product>
<id>1</id>
<name>Monopoly</name>
<price>29.99</price>
<availability>in stock</availability>
<link>http://www.shop.com/product/1</link>
<category>Hobbies | Board Games</category>
</product>Although we call this xml a feed, it is not based on standard formats like Atom or RSS. Our developer site describes not a speficit format but rather the informational content a feed should have. In other words a shop is free to use whatever format it likes for the feed as long as it contains all the information required by Skroutz. Currently for each product indexed it is essential to know:
- UniqueID: it uniquely identifies the product within the shop
- PriceVat: the price of the product, including VAT
- Name: the name of the product
- Link: the shop’s url for the product
- Image: a url of an image for the product
- Category: the category of the product
- Manufacturer: of the product
- Availability: of the product
- Shipping: shipping options and costs
- Size: if applicable (ex XL, L etc)
- Color: if applicable
Some examples from our shops are:
<shop>
<products>
<product>
<name><shop>
<category name="hobbies">
<products>
<product>
<name><shop>
<category name="computers">
<manufacturer name="apple">
<products>
<product>
<name>This flexibility regarding the xml feed format is necessary. Almost every shop indexed by Skroutz has a unique CMS for its products, so the xml feed is unique. We index shops that use hand-edited files, shops that have custom build CMSs, shops that use vendor CMSs, shops that use cloud CMSs, shops that use some combination of the above and the list keeps growing as new shops enter Skroutz.
Of course, this flexibility comes at a cost. Each different xml feed must be adapted to a format acceptable by the internal Skroutz CMS. This process is straightforward but tedious therefore a good candidate for automation. We have therefore developed an internal tool to help integrate a new shop in Skroutz, and now we release a public version of it.
The public validator
The public version of the validator is accessible at https://validator.skroutz.gr.
Currently you can only upload an xml file. The download functionality is restricted to registered users but eventually it will be widely available.
The validation of a xml is done in stages. Each of the following sections will explain them.
The downloader
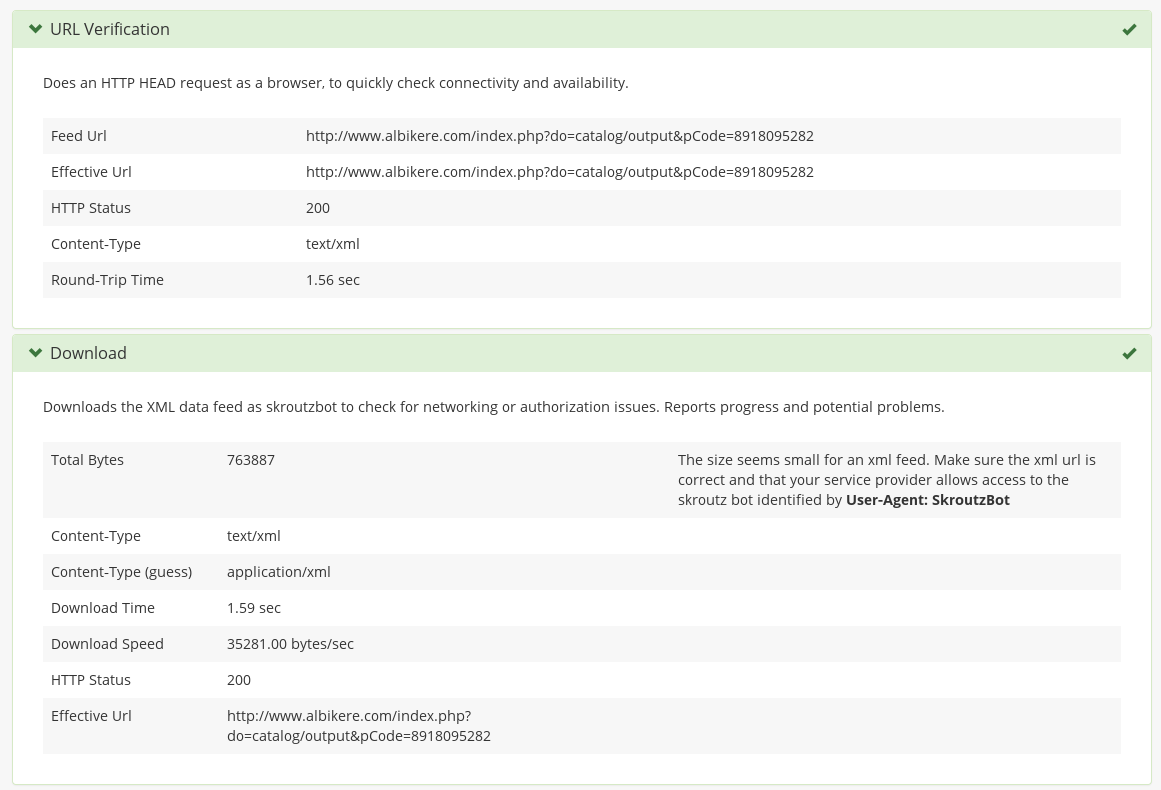
When the validator starts, it tries to download the xml feed. At this stage we want to find and solve problems regarding the network connectivity between the shop and Skroutz. The most common problem is that the shop forbids access to our bot. Other usual cases are broken urls, slow or no connectivity, endless redirection loops and of course all the usual networking troubles and fallacies.
If the downloader step finished with no problems, it reports some useful statistics about the operation. An example is shown in the following screen:
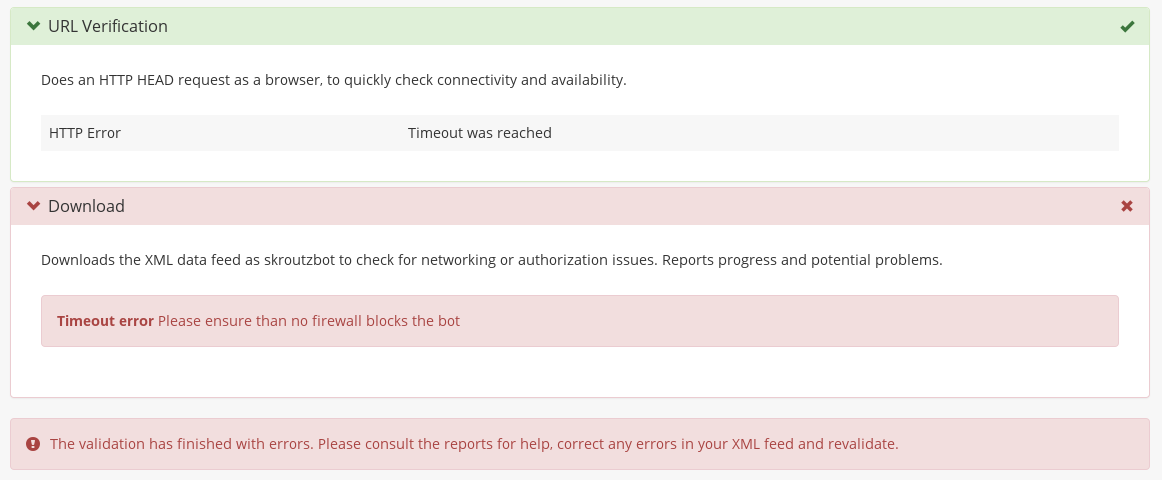
In case of errors, the validation stops, and an appropriate error message is shown, alongside a suggestion on how to fix it.
The uncompressor
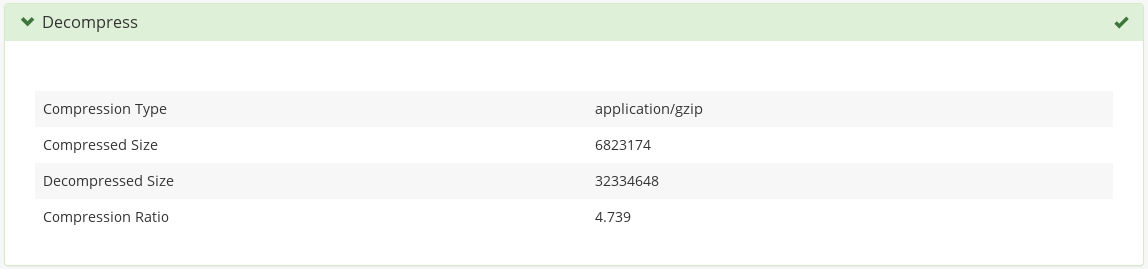
Skroutz accepts .zip and .gz compressed feeds. In case of such a
compressed feed, it validates the integrity of the data and reports
some statistics
The XML verifier
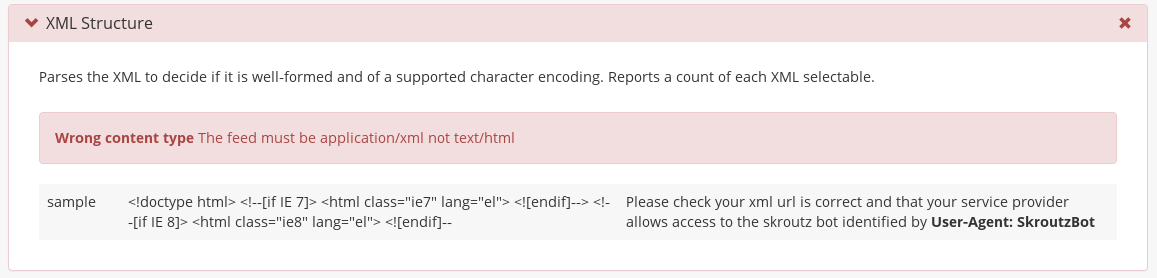
At this point we have downloaded the feed for the shop and we must verify that it’s informational content is compliant with Skroutz standards. The first step is to ensure that the feed is well-formed xml. The most usual error case is that a shop sends us plain html or not well-formed xml. However many HTTP protocol errors are also exposed at this stage. For example a shop may forbid access to the Skroutzbot but mistakenly send an html response with HTTP 200 OK. All these errors are detected and reported here alongside a description of the error and a suggestion to fix it.
An example of an error because of an html feed is
while an example of a not well-formed xml feed is
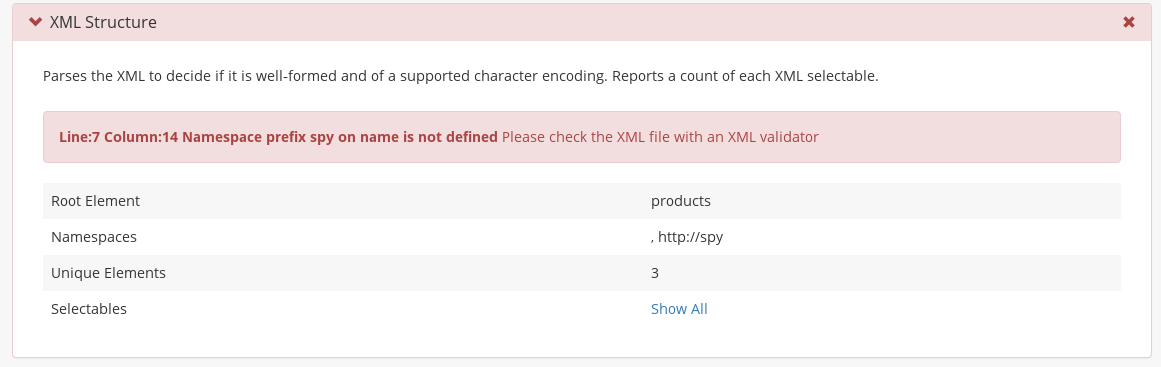
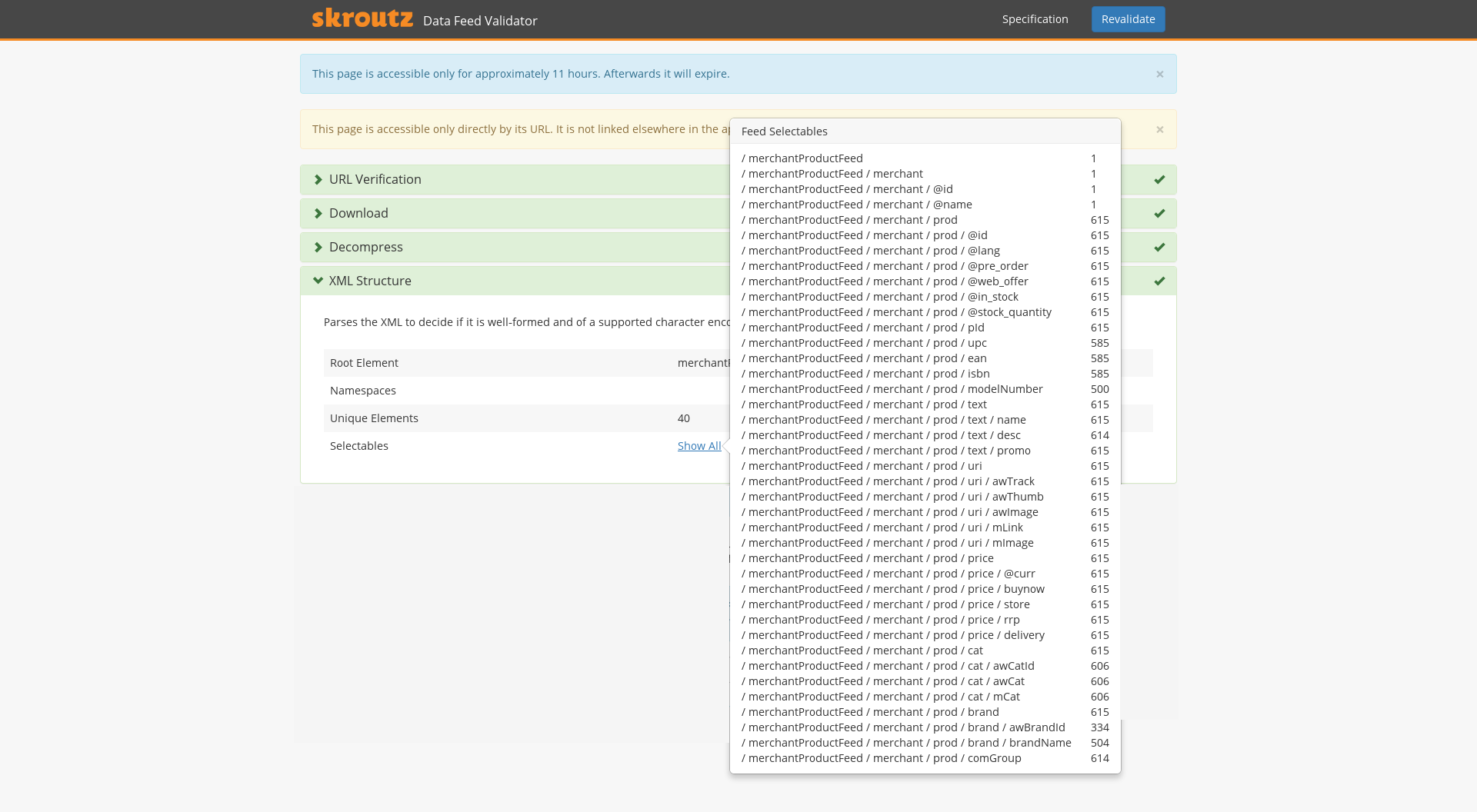
If the feed is indeed well-formed xml, an xml parser scans the feed and reports all the nodes of the xml tree for a quick verification. These nodes, called selectables in our jargon, will be used in the next stage of processing.
The Mapper
The next step is interactive. The validator’s user must match the xml feed’s elements to Skroutz fields. There is only one gotcha. The validator cannot handle every possible xml feed but only a certain class. Specifically it handles only xmls for which a single product node path can be found. This class contains feeds in which all products are defined uniformly using the same xml structure. For example a valid xml is
<shop>
<products>
<product>
<name>in which the product node path is /shop/products/product and every
product is under this path. However a feed like
<shop>
<Technology>
<product>
<name>
<Fashion>
<product>
<name>
</shop>cannot be handled because there isn’t a single product node
path. Some products are defined under /shop/Technology and some under
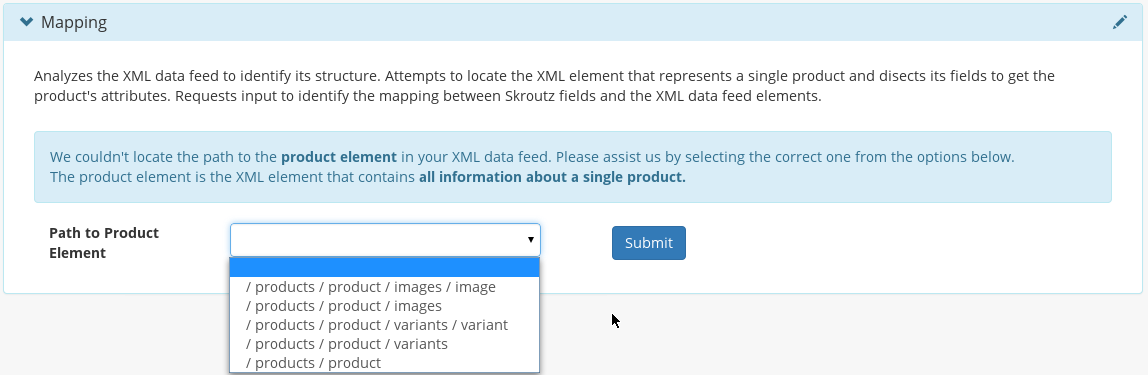
/shop/Fashion. If the validator thinks that the xml feed has more than
1 product node paths then it will ask the user to point to the correct
one. It displays a selection of the possibilities and asks the user for
a decision.
After the definition of the product node path, the validator displays some statistics about the feed and a form to specify the mapping between the xml feed and Skroutz fields. Each element of the form corresponds to one of the properties essential to Skroutz. The user maps this property to the xml selectable that provides the information for it.
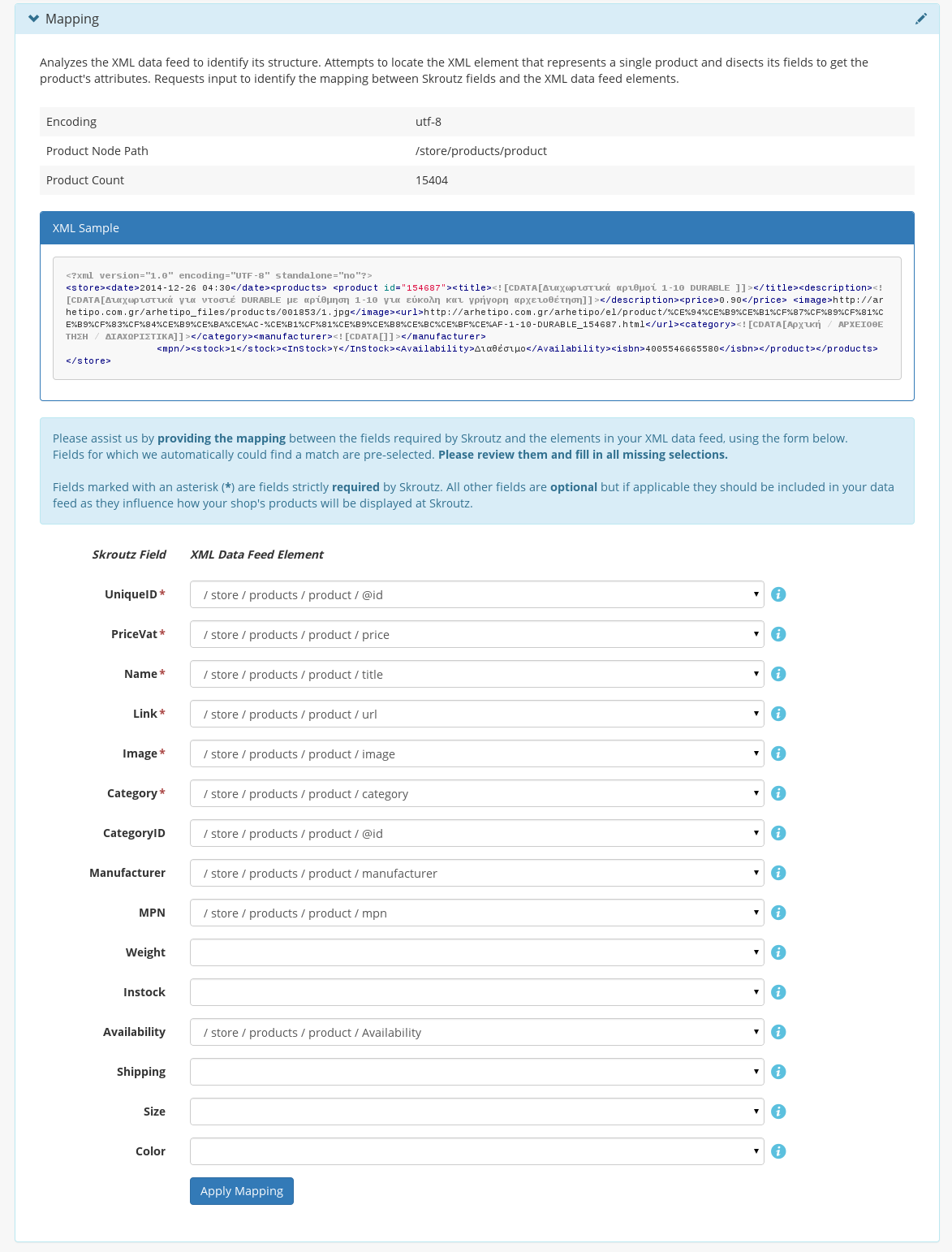
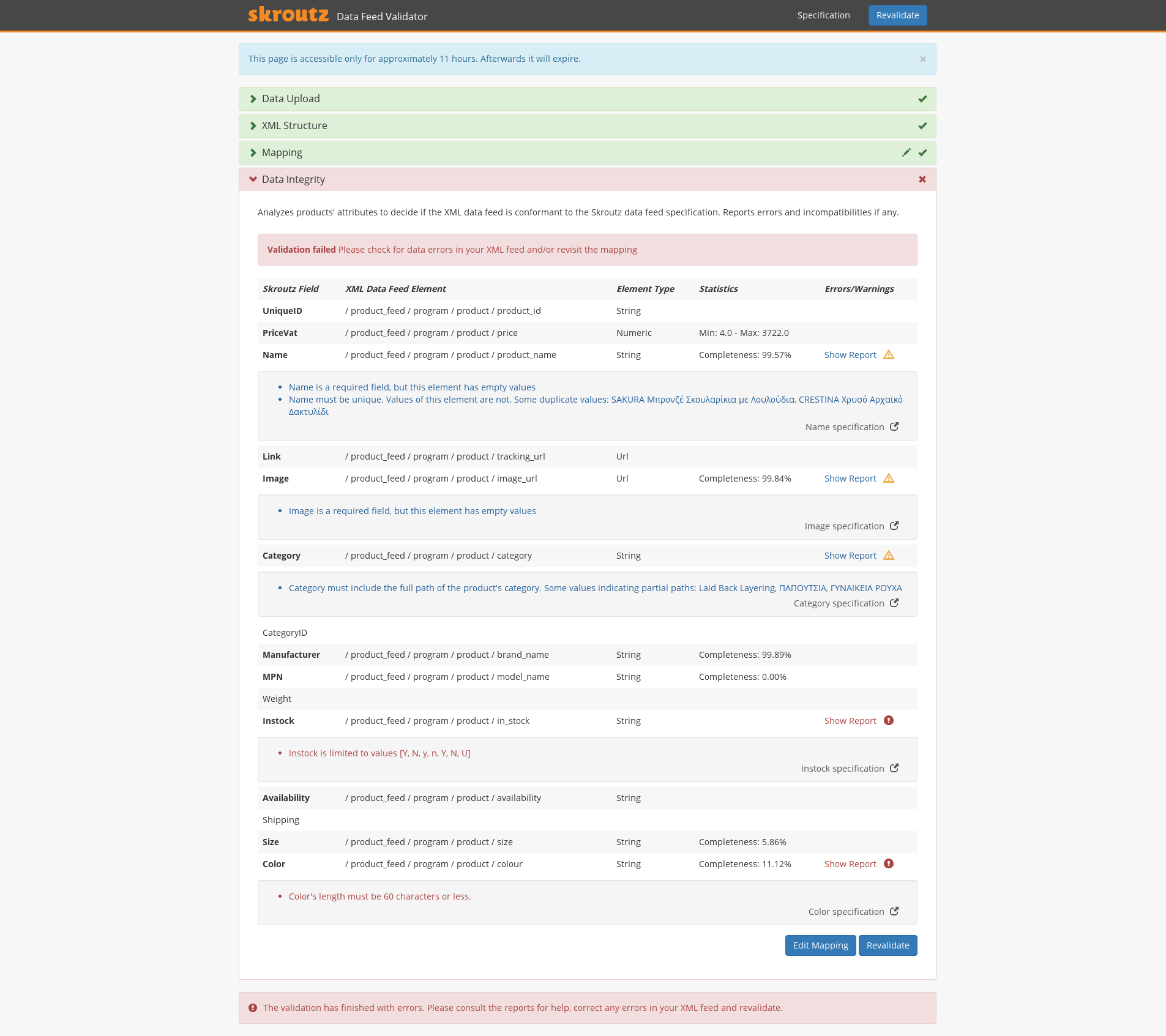
After the mapping is specified, the validator checks all the rules regarding xml feeds with respect to the requirements for each product attribute. Essentially it tries to assert whether each product of the xml feed is ready to be indexed by Skroutz, by examining the product’s data for uniqueness, completeness, data formatting and other criteria. Then it displays a report containing errors, statistics and suggestions that aim to provide insights and reflect a measure of the data feed’s compatibility with the Skroutz index.
Implementation Details
The validator is written using some mainstream technologies, that we favor here at Skroutz. It is written in ruby and uses sinatra as the web framework, bootstrap for the UI and redis for storage.
The bulk of the validator is a workflow engine for the validation. We implemented the engine using resque for the asynchronous processing units, redis for the storage of the intermediate processing results and some ruby metaprogramming for the flow control. These tools provide also good monitoring facilities that we use to monitor the validator.
Why a public validator?
First of all let’s answer a simpler question: Why a validator? Well, the answer is also simple. Tasks that can be automated, must be automated. Good tools that abstract away the details of tedious tasks not only are indispensable but also they are used more frequently and increase the quality of the outcome. In the case of the validator we have observed another aspect of this. The tool acts as a knowledge base for the process of introducing a shop in the Skroutz index. The users of the tool provide feedback regarding types of feed errors, the diagnosis of the tool and the suggestions it makes and this feedback is integrated back in the tool, which thus evolves. We now have a single point of authority regarding products feed which has successully replaced a knowledge base distributed in person, notes, emails, internal wikis, support centers etc.
Now we can answer why a public validator? The answer is straightforward. We want to provide the benefits of the tool to the developers that work with Skroutz xml feeds, helping them to be more productive as they will not devote their time to identify and solve problems with the feed. This will help both developers and Skroutz as it will eliminate the cost of coping with the many iterations of the “find a problem, fix it, retry” cycle. More importantly, however, we aim through the tool to implicitly provide developers with insight to our knowledge base of maintaining the Skroutz index. We firmly believe that this will lead to a better mutual understanding about how our common data should be manipulated and maintained and will prepare the way for additional endpoints to the index like APIs or microservices.
What comes next
The next step it to apply the feedback of the users back to the validator and enhance it. Then we hope to release in public form some other interesting parts of our stack, such as the quality level auditor which further examines the feeds and provides automatic category classification, versioning and many more services.